diff --git a/MD/mpls-vpn实验手册.md b/MD/mpls-vpn实验手册.md
new file mode 100644
index 0000000..e02f0e7
--- /dev/null
+++ b/MD/mpls-vpn实验手册.md
@@ -0,0 +1,262 @@
+
+
+- CE1、CE3属于vpna。
+- CE2、CE4属于vpnb。
+- vpna使用的VPN-target属性为111:1,vpnb为222:2。
+- 不同VPN用户之间不能互相访问。
+
+PE1:
+
+```
+#
+ sysname PE1
+#
+ip vpn-instance vpna //创建VPN实例vpna
+ ipv4-family
+ route-distinguisher 100:1
+ vpn-target 111:1 export-extcommunity
+ vpn-target 111:1 import-extcommunity
+#
+ip vpn-instance vpnb //创建VPN实例vpnb
+ ipv4-family
+ route-distinguisher 100:2
+ vpn-target 222:2 export-extcommunity
+ vpn-target 222:2 import-extcommunity
+#
+mpls lsr-id 1.1.1.9 //配置MPLS
+mpls
+#
+mpls ldp //建立LDP
+#
+interface Ethernet1/0/0 //绑定VPN实例
+ ip binding vpn-instance vpna
+ ip address 10.1.1.2 255.255.255.0
+#
+interface Ethernet2/0/0
+ ip binding vpn-instance vpnb //绑定VPN实例
+ ip address 10.2.1.2 255.255.255.0
+#
+interface Ethernet2/0/1 //接口使能MPLS
+ ip address 172.1.1.1 255.255.255.0
+ mpls
+ mpls ldp
+#
+interface LoopBack1
+ ip address 1.1.1.9 255.255.255.255
+#
+bgp 100 //配置MP-IBGP对等体
+ peer 3.3.3.9 as-number 100
+ peer 3.3.3.9 connect-interface LoopBack1
+ #
+ ipv4-family unicast
+ undo synchronization
+ peer 3.3.3.9 enable
+ #
+ ipv4-family vpnv4 //使能对等体交换VPNv4路由信息的能力
+ policy vpn-target
+ peer 3.3.3.9 enable
+ #
+ ipv4-family vpn-instance vpna //配置PE与CE之间建立EBGP对等体关系,引入VPN路由
+ peer 10.1.1.1 as-number 65410
+ import-route direct
+ #
+ ipv4-family vpn-instance vpnb //配置PE与CE之间建立EBGP对等体关系,引入VPN路由
+ peer 10.2.1.1 as-number 65420
+ import-route direct
+#
+ospf 1 //配置公网路由
+ area 0.0.0.0
+ network 172.1.1.0 0.0.0.255
+ network 1.1.1.9 0.0.0.0
+#
+return
+```
+
+P:
+
+```
+#
+ sysname P
+#
+mpls lsr-id 2.2.2.9 //配置MPLS
+mpls
+#
+mpls ldp
+#
+interface Ethernet1/0/0
+ ip address 172.1.1.2 255.255.255.0
+ mpls
+ mpls ldp
+#
+interface Ethernet2/0/0
+ ip address 172.2.1.1 255.255.255.0
+ mpls
+ mpls ldp
+#
+interface LoopBack1
+ ip address 2.2.2.9 255.255.255.255
+#
+ospf 1 //配置公网路由
+ area 0.0.0.0
+ network 172.1.1.0 0.0.0.255
+ network 172.2.1.0 0.0.0.255
+ network 2.2.2.9 0.0.0.0
+#
+return
+```
+
+PE2:
+
+```
+#
+ sysname PE2
+#
+ip vpn-instance vpna //创建VPN实例vpna
+ ipv4-family
+ route-distinguisher 200:1
+ vpn-target 111:1 export-extcommunity
+ vpn-target 111:1 import-extcommunity
+#
+ip vpn-instance vpnb //创建VPN实例vpnb
+ ipv4-family
+ route-distinguisher 200:2
+ vpn-target 222:2 export-extcommunity
+ vpn-target 222:2 import-extcommunity
+#
+mpls lsr-id 3.3.3.9 //配置MPLS LSR
+mpls
+#
+mpls ldp
+#
+interface Ethernet1/0/0 //绑定VPN实例
+ ip binding vpn-instance vpna
+ ip address 10.3.1.2 255.255.255.0
+#
+interface Ethernet2/0/0 //绑定VPN实例
+ ip binding vpn-instance vpnb
+ ip address 10.4.1.2 255.255.255.0
+#
+interface Ethernet2/0/1 //接口使能MPLS
+ ip address 172.2.1.2 255.255.255.0
+ mpls
+ mpls ldp
+#
+interface LoopBack1
+ ip address 3.3.3.9 255.255.255.255
+#
+bgp 100 //配置MP-IBGP对等体
+ peer 1.1.1.9 as-number 100
+ peer 1.1.1.9 connect-interface LoopBack1
+ #
+ ipv4-family unicast
+ undo synchronization
+ peer 1.1.1.9 enable
+ #
+ ipv4-family vpnv4 //使能对等体交换VPNv4路由信息的能力
+ policy vpn-target
+ peer 1.1.1.9 enable
+ #
+ ipv4-family vpn-instance vpna //配置PE与CE之间建立EBGP对等体关系,引入VPN路由
+ peer 10.3.1.1 as-number 65430
+ import-route direct
+ #
+ ipv4-family vpn-instance vpnb //配置PE与CE之间建立EBGP对等体关系,引入VPN路由
+ peer 10.4.1.1 as-number 65440
+ import-route direct
+#
+ospf 1 //配置公网路由
+ area 0.0.0.0
+ network 172.2.1.0 0.0.0.255
+ network 3.3.3.9 0.0.0.0
+#
+return
+```
+
+CE1:
+
+```
+#
+ sysname CE1
+#
+interface Ethernet1/0/0
+ ip address 10.1.1.1 255.255.255.0
+#
+bgp 65410 //在PE与CE之间建立EBGP对等体关系
+ peer 10.1.1.2 as-number 100
+ #
+ ipv4-family unicast
+ undo synchronization
+ import-route direct //引入直连路由
+ peer 10.1.1.2 enable
+#
+return
+```
+
+CE2:
+
+```
+#
+ sysname CE2
+#
+interface Ethernet1/0/0
+ ip address 10.2.1.1 255.255.255.0
+#
+bgp 65420 //在PE与CE之间建立EBGP对等体关系
+ peer 10.2.1.2 as-number 100
+ #
+ ipv4-family unicast
+ undo synchronization
+ import-route direct //引入直连路由
+ peer 10.2.1.2 enable
+#
+return
+```
+
+CE3:
+
+```
+#
+ sysname CE3
+#
+interface Ethernet1/0/0
+ ip address 10.3.1.1 255.255.255.0
+#
+bgp 65430 //在PE与CE之间建立EBGP对等体关系
+ peer 10.3.1.2 as-number 100
+ #
+ ipv4-family unicast
+ undo synchronization
+ import-route direct //引入直连路由
+ peer 10.3.1.2 enable
+#
+return
+```
+
+CE4:
+
+```
+#
+ sysname CE4
+#
+interface Ethernet1/0/0
+ ip address 10.4.1.1 255.255.255.0
+#
+bgp 65440 //在PE与CE之间建立EBGP对等体关系
+ peer 10.4.1.2 as-number 100
+ #
+ ipv4-family unicast
+ undo synchronization
+ import-route direct //引入直连路由
+ peer 10.4.1.2 enable
+#
+return
+```
+
+PE之间必须使用32位掩码的Loopback接口地址来建立MP-IBGP对等体关系,以便能够迭代到隧道
+
+
+
+
+
+
+
diff --git a/MD/第十一章:MPLS VPN技术.md b/MD/第十一章:MPLS VPN技术.md
new file mode 100644
index 0000000..5cae1fe
--- /dev/null
+++ b/MD/第十一章:MPLS VPN技术.md
@@ -0,0 +1,900 @@
+MPLS VPN技术
+
+> 作者:行癫
+
+------
+
+第一节:MPLS VPN原理与配置
+
+一:MPLS VPN概述
+
+1.MPLS VPN定义
+
+ BGP/MPLS IP VPN网络一般由运营商搭建,VPN用户购买VPN服务来实现用户网络之间的路由传递、数据互通等
+
+ MPLS VPN使用BGP在运营商骨干网上发布VPN路由,使用MPLS在运营商骨干网上转发VPN报文,BGP/MPLS IP VPN又被简称为MPLS VPN
+
+ +
+
+
+2.MPLS VPN网络架构
+
+ MPLS VPN网络架构由三部分组成:CE(Customer Edge)、PE(Provider Edge)和P(Provider),其中PE和P是运营商设备,CE是MPLS VPN用户设备
+
+ 站点(site)就是MPLS VPN的用户,由CE和其他用户设备构成
+
+
+
+ CE:用户网络边缘设备,有接口直接与运营商网络相连。CE可以是路由器或交换机,也可以是一台主机。通常情况下,CE“感知”不到VPN的存在,也不需要支持MPLS
+
+ PE:运营商边缘路由器,是运营商网络的边缘设备,与CE直接相连。在MPLS网络中,对VPN的所有处理都发生在PE上,对PE性能要求较高
+
+ P:运营商网络中的骨干路由器,不与CE直接相连。P设备只需要具备基本MPLS转发能力,不维护VPN相关信息
+
+**站点的含义可以从下述几个方面理解:**
+
+ 站点是指相互之间具备IP连通性的一组IP系统,并且这组IP系统的IP连通性不需通过运营商网络实现
+
+ 站点的划分是根据设备的拓扑关系,而不是地理位置。如图所示,公司A的X省网络和公司A的Y省网络需要通过运营商的骨干网进行互联,所以它们被划分为两个站点。若在当前X省网络和Y省网络的CE之间增加一条物理专线,不需要通过运营商网络就可以互通,那么这两张网络就是一个站点
+
+**站点与VPN的关系:**
+
+ 对于多个连接到同一服务提供商网络的站点,通过制定策略,可以将它们划分为不同的集合,只有属于相同集合的站点之间才能通过服务提供商网络互访,这种集合就是VPN
+
+ 一个Site中的设备可以属于多个VPN,换言之,一个Site可以属于多个VPN
+
+3.MPLS VPN技术架构
+
+MPLS VPN不是单一的一种VPN技术,是多种技术结合的综合解决方案,主要包含下列技术:
+
+ MP-BGP:负责在PE与PE之间传递站点内的路由信息
+
+ LDP:负责PE与PE之间的隧道建立
+
+ VRF:负责PE的VPN用户管理
+
+ 静态路由、IGP、BGP:负责PE与CE之间的路由信息交换
+
+
+
+4.为什么要选择MPLS VPN
+
+**对VPN客户而言:**
+
+ “感知”不到VPN的存在,不需要部署和维护VPN,降低企业运维难度和成本
+
+ 一般部署在运营商的MPLS VPN专网上,有一定的安全性保障
+
+**对于运营商而言:**
+
+ MPLS在无连接的IP网络中增加了面向连接的控制平面,为IP网络增添了管理和运营的手段
+
+ 支持地址空间重叠、支持重叠VPN、组网方式灵活、可扩展性好
+
+ 能够方便地支持MPLS TE合理调控现有网络资源,最大限度的节省运营商成本
+
+ MPLS TE(MPLS Traffic Engineering,MPLS流量工程):基于一定约束条件LSP隧道,并将流量引入到这些隧道中进行转发,使网络流量按照指定的路径进行传输。可以在不进行硬件升级的情况下对现有网络资源进行合理调配和利用,并对网络流量提供带宽和QoS保证,最大限度的节省成本
+
+5.MPLS VPN常见组网
+
+根据VPN用户的需求不同,可采用以下几种常见的组网方案:
+
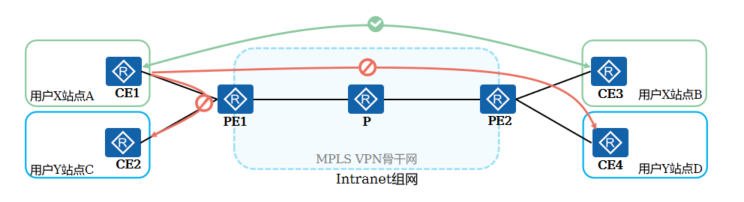
+ Intranet:一个VPN中的所有用户形成闭合用户群,同一VPN站点之间可以互访,不同VPN站点间不能互访
+
+ Extranet:适用于一个VPN用户希望提供部分本VPN的站点资源给其他VPN的用户访问的场景
+
+ Hub&Spoke:如果希望在VPN中设置中心访问控制设备,其它用户的互访都通过中心访问控制设备进行,可采用Hub&Spoke组网方案
+
+
+
+二:MPLS VPN路由交互
+
+1.MPLS VPN路由发布概述
+
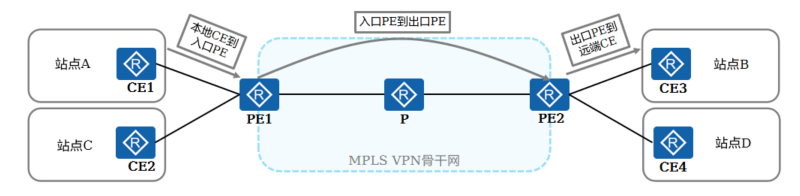
+ 若想实现同一个VPN的不同站点之间的通信,首先需要完成不同站点之间的路由交互。在基本MPLS VPN组网中,VPN路由信息的发布涉及CE和PE,P路由器只维护骨干网的路由,不需要了解任何VPN路由信息。VPN路由信息的发布过程包括三部分:
+
+ 本地CE到入口PE
+
+ 入口PE到出口PE
+
+ 出口PE到远端CE
+
+
+
+2.CE与PE之间的路由信息交换
+
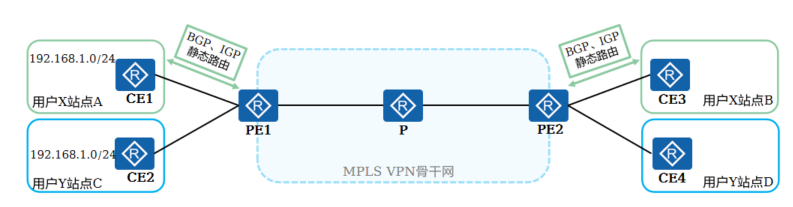
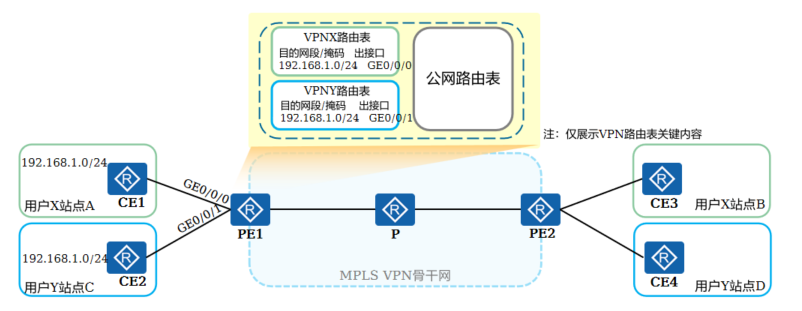
+ 如图,客户X和客户Y属于不同的VPN,分别拥有两个站点,现需要实现站点间的路由信息交互
+
+ CE与PE之间可以使用静态路由、OSPF、IS-IS或BGP交换路由信息。无论使用哪种路由协议,CE和PE之间交换的都是标准的IPv4路由
+
+ 本地CE到入口PE和出口PE到远端CE的路由信息交换原理完全相同
+
+
+
+3.入口PE到出口PE路由传递(1)
+
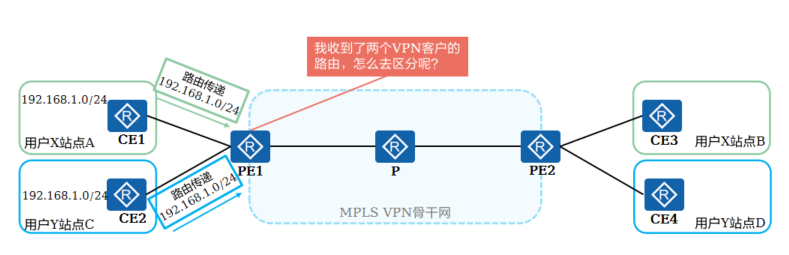
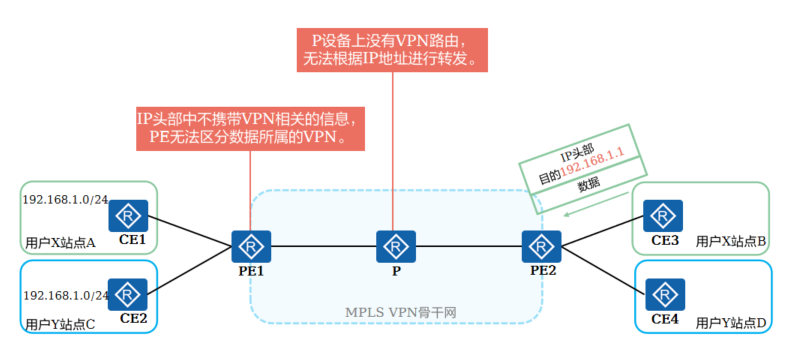
+ PE在接收到CE传递来的路由之后,需要独立保存不同VPN的路由,且需要解决不同的客户使用重叠IP地址空间的问题
+
+
+
+ VPN是一种私有网络,不同的VPN独立管理自己的地址范围,也称为地址空间(address space)。不同VPN的地址空间可能会在一定范围内重合,例如图中用户X和用户Y都使用192.168.1.0/24网段地址,这就发生了地址空间的重叠
+
+**以下两种情况允许VPN使用重叠的地址空间:**
+
+ 两个VPN没有共同的站点
+
+ 两个VPN有共同的站点,但此共同站点中的设备不与两个VPN中使用重叠地址空间的设备互访
+
+**VRF**
+
+ VRF(Virtual Routing and Forwarding,虚拟路由转发),又称VPN实例,是MPLS VPN架构中的关键技术,每个VPN实例使用独立的路由转发表项,实现VPN之间的逻辑隔离
+
+
+
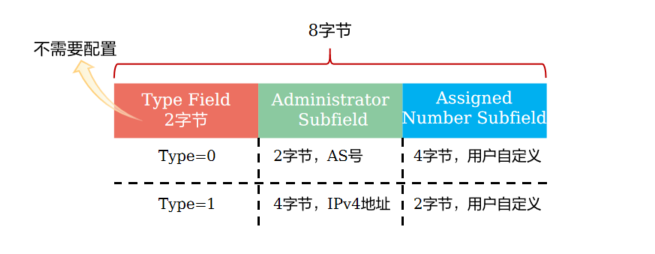
+**RD**
+
+ PE收到不同VPN的CE发来的IPv4地址前缀,本地根据VPN实例配置去区分这些地址前缀。但是VPN实例只是一个本地的概念,PE无法将VPN实例信息传递到对端PE,故有了RD(Route Distinguisher,路由标识符)
+
+ RD长8字节,用于区分使用相同地址空间的IPv4前缀
+
+ PE从CE接收到IPv4路由后,在IPv4前缀前加上RD,转换为全局唯一的VPN-IPv4路由
+
+
+
+注意:
+
+ 配置RD时,只需要指定RD的Administrator子字段和Assigned Number子字段
+
+ RD的配置格式有四种,常用的两种如下:
+
+ 16bits自治系统号:32bits用户自定义数字(例如:100:1)
+
+ 32bits IPv4地址:16bits用户自定义数字(例如:172.1.1.1:1)
+
+ RD的结构使得每个运营商可以独立地分配RD,但为了在某些应用场景下保证路由正常,必须保证RD全局唯一
+
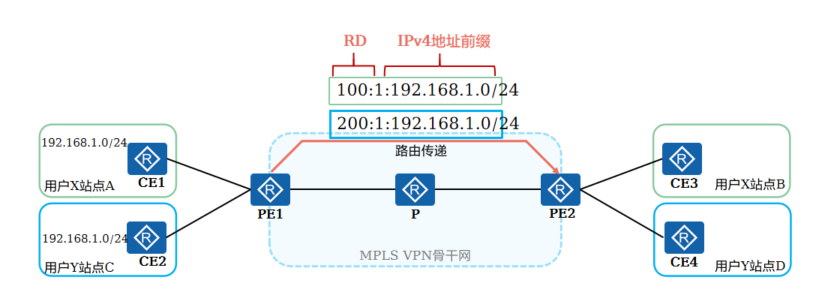
+**VPN-IPv4地址**
+
+ VPN-IPv4地址又被称为VPNv4地址:VPNv4地址共有12个字节,包括8字节的路由标识符RD(Route Distinguisher)和4字节的IPv4地址前缀
+
+
+
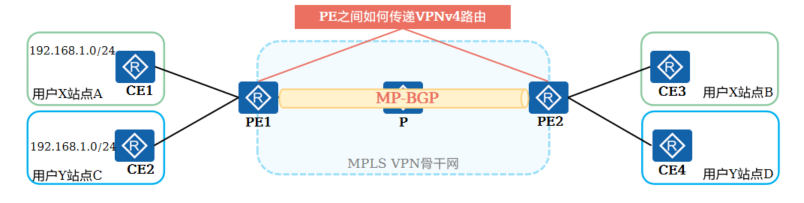
+4.入口PE到出口PE路由传递(2)
+
+PE之间建立BGP邻居关系,并通过BGP进行路由传递。为什么采用BGP呢?
+
+ BGP使用TCP作为其传输层协议,提高了协议的可靠性。可以跨路由器的两个PE设备之间直接交换路由
+
+ BGP拓展性强,为PE间传播VPN路由提供了便利
+
+ PE之间需要传送的路由条目可能较大,BGP只发送更新的路由,提高传递路由数量的同时不占用过多链路带宽
+
+传统的BGP-4不支持处理VPNv4路由
+
+
+
+**MP-BGP**
+
+ 为了正确处理VPN路由,MPLS VPN使用RFC2858(Multiprotocol Extensions for BGP-4)中规定的MP-BGP,即BGP-4的多协议扩展
+
+ MP-BGP采用地址族(Address Family)来区分不同的网络层协议,既可以支持传统的IPv4地址族,又可以支持其它地址族(比如VPN-IPv4地址族、IPv6地址族等)
+
+**MP-BGP新增了两种路径属性:**
+
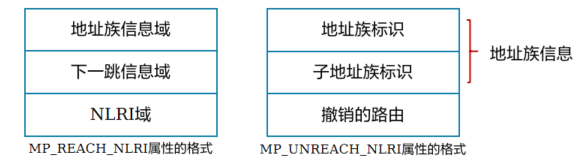
+ MP_REACH_NLRI:Multiprotocol Reachable NLRI,多协议可达NLRI。用于发布可达路由及下一跳信息
+
+ MP_UNREACH_NLRI:Multiprotocol Unreachable NLRI,多协议不可达NLRI。用于撤销不可达路由
+
+
+
+**注意:**
+
+NLRI:Network Layer Reachability Information,网络层可达信息
+
+关于地址族的一些取值请参考RFC3232(Assigned Numbers)
+
+MP_REACH_NLRI用于发布可达路由及下一跳信息。该属性由一个或多个三元组组成,格式如下:
+
+ 地址族信息(Address Family Information)域:由2字节的地址族标识AFI(Address Family Identifier)和1字节的子地址族标识SAFI(Subsequent Address Family Identifier)组成
+
+ 下一跳信息(Next Hop Network Address Information)域:由一字节的下一跳网络地址长度和可变长度的下一跳网络地址组成
+
+ 网络层可达性信息(NLRI)域:由一个或多个三元组<长度、标签、前缀>组成
+
+MP_UNREACH_NLRI用于通知对等体删除不可达的路由。该属性的格式如下:
+
+ 地址族标识AFI:与MP_REACH_NLRI属性中的相同
+
+ 子地址族标识SAFI:与MP_REACH_NLRI属性中的相同,表示NLRI的类型
+
+ 撤销路由(Withdrawn Routes):不可达路由列表,也是由一个或多个NLRI组成。BGP发言者可以通过在撤销路由域中携带与之前发布的可达路由中相同的NLRI来撤销路由
+
+MP-BGP的报文类型、VPNv4路由发布策略仍与普通BGP相同
+
+5.入口PE到出口PE路由传递 (3)
+
+ MP-BGP将VPNv4传递到远端PE之后,远端PE需要将VPNv4路由导入正确的VPN实例
+
+ MPLS VPN使用BGP扩展团体属性-VPN Target(也称为Route Target)来控制VPN路由信息的发布与接收
+
+ 本地PE在发布VPNv4路由前附上RT属性,对端PE在接到VPNv4路由后根据RT将路由导入对应的VPN实例
+
+
+
+**RT**
+
+在PE上,每一个VPN实例都会与一个或多个VPN Target属性绑定,有两类VPN Target属性:
+
+ Export Target(ERT):本地PE从直接相连站点学到IPv4路由后,转换为VPN IPv4路由,并为这些路由添加Export Target属性。Export Target属性作为BGP的扩展团体属性随路由发布
+
+ Import Target(IRT):PE收到其它PE发布的VPN-IPv4路由时,检查其Export Target属性。当此属性与PE上某个VPN实例的Import Target匹配时,PE就把路由加入到该VPN实例的路由表
+
+
+
+6.入口PE到出口PE路由传递 (4)
+
+ PE根据VPNv4路由所携带的RT将路由导入正确的VPN实例之后,VPNv4路由的RD值剥除,将IPv4路由通告给相应的客户的CE设备
+
+ 站点B和站点D的CE设备就能学习到去往各自远端站点的路由。同理,通过一系列的操作,可以实现同一用户(同一VPN)不同站点之间的路由互通
+
+
+
+7.数据转发时遇到的问题
+
+
+
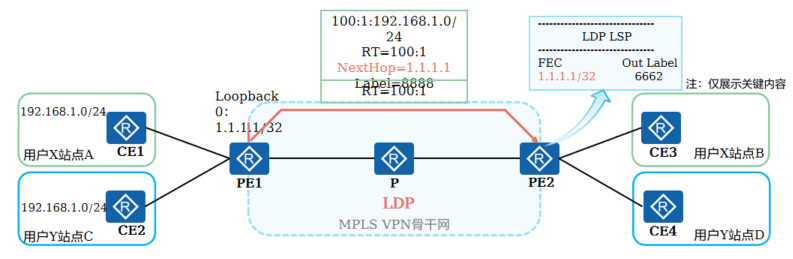
+8.入口PE到出口PE路由传递 (5)
+
+ PE和P设备之间运行LDP,交换公网标签,建立PE之间的LSP隧道(公网隧道)
+
+ 入口PE在通过MP-BGP传递VPNv4路由时,会携带私网标签,用于区分不同VPN的数据
+
+ 出口PE在接收到VPNv4路由后,需要执行私网路由交叉和隧道迭代来选择路由
+
+
+
+**PE上分配私网标签的方法有如下两种:**
+
+ 基于路由的MPLS标签分配:为VPN路由表的每一条路由分配一个标签(one label per route)。这种方式的缺点是:当路由数量比较多时,设备入标签映射表ILM(Incoming Label Map)需要维护的表项也会增多,从而提高了对设备容量的要求
+
+ 基于VPN实例的MPLS标签分配:为整个VPN实例分配一个标签,该VPN实例里的所有路由都共享一个标签。使用这种分配方法的好处是节约了标签
+
+ 私网路由交叉:VPNv4路由与本地VPN实例的VPN-Target进行匹配的过程称为私网路由交叉。PE在收到VPNv4路由后,既不进行优选,也不检查隧道是否存在,直接将其与本地的VPN实例进行交叉
+
+ 隧道迭代:为了将私网流量通过公网传递到另一端,需要有一条公网隧道承载这个私网流量。因此私网路由交叉完成后,需要根据目的IPv4前缀进行路由迭代,即该IPv4路由的下一跳有对应的LSP存在;只有隧道迭代成功,该路由才被放入对应的VPN实例路由表
+
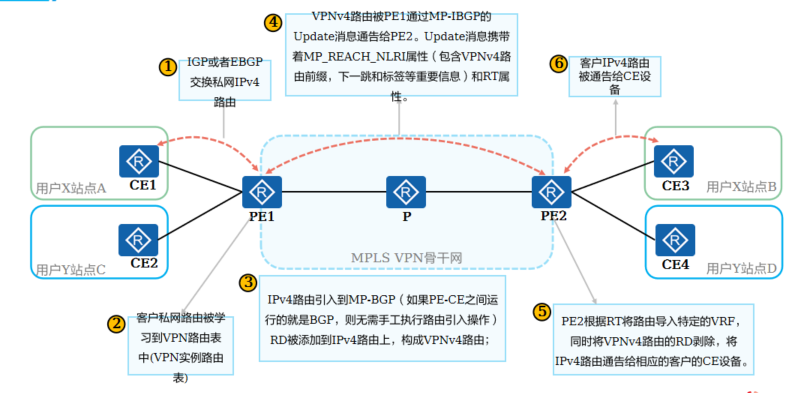
+9.MPLS VPN中的路由交互全过程
+
+
+
+ IGP或者EBGP交换私网IPv4路由
+
+ 客户私网路由被学习到VPN路由表中(VPN实例路由表)
+
+ IPv4路由引入到MP-BGP(如果PE-CE之间运行的就是BGP,则无需手工执行路由引入操作)
+RD被添加到IPv4路由上,构成VPNv4路由;
+
+ VPNv4路由被PE1通过MP-IBGP的Update消息通告给PE2。Update消息携带着MP_REACH_NLRI属性(包含VPNv4路由前缀,下一跳和标签等重要信息)和RT属性。
+
+ PE2根据RT将路由导入特定的VRF,同时将VPNv4路由的RD剥除,将IPv4路由通告给相应的客户的CE设备
+
+ 客户IPv4路由被通告给CE设备
+
+三:MPLS VPN报文转发
+
+1.报文转发过程 (1)
+
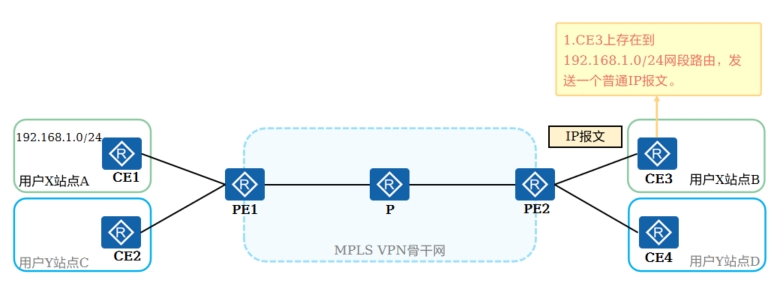
+以图中用户X的站点B访问站点A的192.168.1.0/24网段为例,报文转发过程如下:
+
+
+
+2.报文转发过程 (2)
+
+
+
+ PE2根据报文入接口找到VPN实例,查找对应VPN的转发表
+
+ 匹配目的IPv4前缀,并打上对应的内层标签(I-L)
+
+ 根据下一跳地址,查找对应的Tunnel-ID
+
+ 将报文从隧道发送出去,即打上公网(外层)MPLS标签头(O-L1)
+
+3.报文转发过程 (3)
+
+
+
+ 骨干网的所有P设备都对该报文进行外层标签交换,直到到达PE1
+
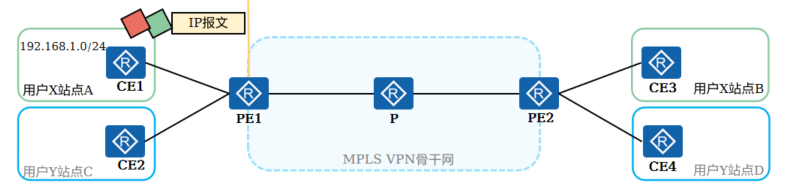
+4.报文转发过程 (4)
+
+
+
+ PE1收到该携带两层标签的报文,交给MPLS处理,MPLS协议将去掉外层标签
+
+ PE1继续处理内层标签:根据内层标签确定对应的下一跳,并将内层标签剥离后,以纯IPv4报文的形式发送给CE1
+
+5.报文转发过程 (5)
+
+
+
+ CE1收到该IPv4报文后,进行常规的IPv4处理流程
+
+四:MPLS VPN配置与实现
+
+1.配置命令 - VPN实例配置
+
+
+
+
+
+2.配置命令 - MP-BGP配置
+
+
+
+3.配置命令 - PE与CE间路由配置
+
+
+
+4.MPLS VPN配置示例 - 背景介绍
+
+
+
+ 客户X及Y各自有2个站点,现需要通过MPLS VPN实现站点之间的互联,分别对应VPNX和VPNY
+
+ 互联接口、AS号及IP地址信息如图
+
+ 客户X站点与PE之间采用OSPF交互路由信息,客户Y站点与PE之间采用BGP交互路由信息
+
+5.MPLS VPN配置示例 - 配置思路
+
+**MPLS VPN骨干网配置**
+
+ IGP配置,实现骨干网的IP连通性
+
+ MPLS与MPLS LDP配置,建立MPLS LSP公网隧道,传输VPN数据
+
+ MP-BGP配置,建立后续传递VPNv4路由的MP-BGP对等体关系
+
+**VPN用户接入配置**
+
+ 创建VPN实例并配置参数(RT、RD)
+
+ 将接口加入VPN实例
+
+ 配置PE与CE之间的路由交换
+
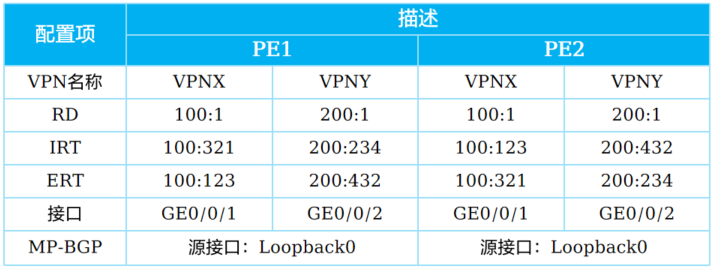
+6.MPLS VPN配置示例 - 数据规划
+
+ MPLS骨干网采用单区域OSPF实现路由互通,所有PE和P互联接口均使能MPLS LDP功能
+
+**PE上的VPN相关配置如表格:**
+
+
+
+7.部署配置
+
+**MPLS VPN骨干网配置**
+
+ 在MPLS VPN骨干网络内部署OSPF,MPLS VPN骨干网络内部署的OSPF用于实现骨干网络内部的路由互通
+
+ 以PE1节点的OSPF配置为例
+
+```shell
+[PE1]ospf 100 router-id 1.1.1.1
+[PE1-ospf-100]area 0
+[PE1-ospf-100-area-0.0.0.0]network 10.0.12.1 0.0.0.0
+[PE1-ospf-100-area-0.0.0.0]network 1.1.1.1 0.0.0.0
+```
+
+ 在PE1、P、PE2节点配置MPLS及LDP,以PE1为例
+
+```shell
+[PE1]mpls lsr-id 1.1.1.1
+[PE1]mpls
+Info: Mpls starting, please wait... OK!
+[PE1-mpls]mpls ldp
+[PE1-mpls-ldp]Interface GigabitEthernet 0/0/0
+[PE1-GigabitEthernet0/0/0]mpls
+[PE1-GigabitEthernet0/0/0]mpls ldp
+```
+
+ 在PE1及PE2之间建立MP-BGP对等体关系,以PE1为例
+
+```shell
+[PE1]bgp 123
+[PE1-bgp]router-id 1.1.1.1
+[PE1-bgp]peer 3.3.3.3 as-number 123
+[PE1-bgp]peer 3.3.3.3 connect-interface LoopBack 0
+#进入BGP-VPNv4地址族视图,并使能与对等体3.3.3.3的VPNv4地址族能力。
+[PE1-bgp]ipv4-family vpnv4 unicast
+[PE1-bgp-af-vpnv4]peer 3.3.3.3 enable
+```
+
+**MPLS VPN骨干网配置 - 配置验证**
+
+ 查看公网隧道建立情况
+
+```shell
+[PE1]display mpls lsp
+-------------------------------------------------------------------------------
+LSP Information: LDP LSP
+-------------------------------------------------------------------------------
+FEC In/Out Label In/Out IF Vrf Name
+3.3.3.3/32 NULL/1025 -/GE0/0/0
+1.1.1.1/32 3/NULL -/-
+```
+
+```shell
+[PE2]display mpls lsp
+-------------------------------------------------------------------------------
+LSP Information: LDP LSP
+-------------------------------------------------------------------------------
+FEC In/Out Label In/Out IF Vrf Name
+3.3.3.3/32 3/NULL -/-
+1.1.1.1/32 NULL/1024 -/GE0/0/0
+```
+
+ 查看MP-BGP邻居状态,以PE1为例
+
+```shell
+[PE1]display bgp vpnv4 all peer
+ BGP local router ID : 1.1.1.1
+ Local AS number : 123
+ Total number of peers : 1 Peers in established state : 1
+
+ Peer V AS MsgRcvd MsgSent OutQ Up/Down State Pre fRcv
+ 3.3.3.3 4 123 16 18 0 00:14:20 Established 0
+```
+
+**VPN用户接入配置**
+
+ 创建VPN实例并按照规划配置RD与RT参数,以PE1为例
+
+```shell
+[PE1]ip vpn-instance VPNX
+[PE1-vpn-instance-VPNX]route-distinguisher 100:1
+[PE1-vpn-instance-VPNX-af-ipv4] vpn-target 100:321 import-extcommunity
+ IVT Assignment result:
+Info: VPN-Target assignment is successful.
+[PE1-vpn-instance-VPNX-af-ipv4]vpn-target 100:123 export-extcommunity
+ EVT Assignment result:
+Info: VPN-Target assignment is successful.
+[PE1-vpn-instance-VPNX-af-ipv4] quit
+[PE1-vpn-instance-VPNX]quit
+[PE1]ip vpn-instance VPNY
+[PE1-vpn-instance-VPNY]route-distinguisher 200:1
+[PE1-vpn-instance-VPNY-af-ipv4]vpn-target 200:234 import-extcommunity
+[PE1-vpn-instance-VPNY-af-ipv4]vpn-target 200:432 export-extcommunity
+[PE1-vpn-instance-VPNY-af-ipv4]quit
+[PE1-vpn-instance-VPNY]quit
+```
+
+ 将接口绑定到VPN实例
+
+```shell
+[PE1]interface GigabitEthernet 0/0/1
+[PE1-GigabitEthernet0/0/1]ip binding vpn-instance VPNX
+Info: All IPv4 related configurations on this interface are removed!
+Info: All IPv6 related configurations on this interface are removed!
+[PE1-GigabitEthernet0/0/1]ip address 192.168.100.2 24
+[PE1-GigabitEthernet0/0/1]interface GigabitEthernet 0/0/2
+[PE1-GigabitEthernet0/0/2]ip binding vpn-instance VPNY
+Info: All IPv4 related configurations on this interface are removed!
+Info: All IPv6 related configurations on this interface are removed!
+[PE1-GigabitEthernet0/0/2]ip address 192.168.100.2 24
+```
+
+ 部署CE1-PE1、CE3-PE2间的路由信息交互,以PE1为例
+
+```shell
+#创建与实例绑定的OSPF进程
+[PE1]ospf 2 vpn-instance VPNX
+[PE1-ospf-2]area 0
+[PE1-ospf-2-area-0.0.0.0]network 192.168.100.0 0.0.0.255
+[PE1-ospf-2-area-0.0.0.0]quit
+```
+
+```shell
+#配置OSPF进程与MP-BGP之间的路由双向引入
+[PE1]ospf 2 vpn-instance VPNX
+[PE1-ospf-2]import-route bgp
+[PE1-ospf-2]quit
+[PE1]bgp 123
+[PE1-bgp]ipv4-family vpn-instance VPNX
+[PE1-bgp-VPNX]import-route ospf 2
+```
+
+ 部署CE2-PE1、CE4-PE2间的路由信息交互,以CE2和PE1为例
+
+```shell
+#配置CE2上的EBGP,并引入直连路由192.168.1.0/24
+[CE2]BGP 200
+[CE2-bgp]peer 192.168.100.2 as-number 123
+[CE2-bgp]network 192.168.1.0 24
+[CE2-bgp]quit
+```
+
+```shell
+#配置PE1上VPN实例的EBGP对等体
+[PE1]bgp 123
+[PE1-bgp]ipv4-family vpn-instance VPNY
+[PE1-bgp-VPNY]peer 192.168.100.1 as-number 200
+```
+
+**配置验证**
+
+ 查看VPNX用户的CE路由学习情况
+
+```shell
+[CE1]display ip routing-table
+Route Flags: R - relay, D - download to fib
+------------------------------------------------------------------------------
+Destination/Mask Proto Pre Cost Flags NextHop Interface
+192.168.1.0/24 Direct 0 0 D 192.168.1.254 GigabitEthernet0/0/1
+192.168.2.0/24 OSPF 10 4 D 192.168.100.2 GigabitEthernet0/0/0
+192.168.100.0/24 Direct 0 0 D 192.168.100.1 GigabitEthernet0/0/0
+192.168.200.0/24 O_ASE 150 1 D 192.168.100.2 GigabitEthernet0/0/0
+```
+
+```shell
+[CE3]dis ip routing-table
+Route Flags: R - relay, D - download to fib
+------------------------------------------------------------------------------
+Destination/Mask Proto Pre Cost Flags NextHop Interface
+192.168.1.0/24 OSPF 10 4 D 192.168.200.2 GigabitEthernet0/0/0
+192.168.2.0/24 Direct 0 0 D 192.168.2.254 GigabitEthernet0/0/1
+192.168.100.0/24 O_ASE 150 1 D 192.168.200.2 GigabitEthernet0/0/0
+192.168.200.0/24 Direct 0 0 D 192.168.200.1 GigabitEthernet0/0/0
+```
+
+ 查看VPNY用户的CE路由学习情况
+
+```shell
+[CE2]display ip routing-table
+Route Flags: R - relay, D - download to fib
+------------------------------------------------------------------------------
+Destination/Mask Proto Pre Cost Flags NextHop Interface
+192.168.1.0/24 Direct 0 0 D 192.168.1.254 GigabitEthernet0/0/1
+192.168.2.0/24 EBGP 255 0 D 192.168.100.2 GigabitEthernet0/0/0
+192.168.100.0/24 Direct 0 0 D 192.168.100.1 GigabitEthernet0/0/0
+```
+
+```shell
+[CE4]display ip routing-table
+Route Flags: R - relay, D - download to fib
+------------------------------------------------------------------------------
+Destination/Mask Proto Pre Cost Flags NextHop Interface
+192.168.2.0/24 Direct 0 0 D 192.168.1.254 GigabitEthernet0/0/1
+192.168.1.0/24 EBGP 255 0 D 192.168.100.2 GigabitEthernet0/0/0
+192.168.200.0/24 Direct 0 0 D 192.168.100.1 GigabitEthernet0/0/0
+```
+
+```shell
+[PE2] display bgp vpnv4 vpn-instance VPNX routing-table 192.168.1.0 24
+
+ BGP local router ID : 3.3.3.3
+ Local AS number : 123
+ VPN-Instance VPNX, Router ID 3.3.3.3:
+ Paths: 1 available, 1 best, 1 select
+ BGP routing table entry information of 192.168.1.0/24:
+ Label information (Received/Applied): 1026/NULL
+ From: 1.1.1.1 (1.1.1.1)
+Relay token: 0x1
+ Original nexthop: 1.1.1.1
+```
+
+```shell
+[PE2]display mpls lsp
+-------------------------------------------------------------------------------
+LSP Information: LDP LSP
+-------------------------------------------------------------------------------
+FEC In/Out Label In/Out IF Vrf Name
+1.1.1.1/32 NULL/1024 -/GE0/0/0
+1.1.1.1/32 1024/1024 -/GE0/0/0
+```
+
+ 以192.168.2.0/24网段到192.168.1.0/24网段的数据为例,外层标签为1024,由MPLS LDP分配。内层标签为1026,由MP-BGP分配
+
+```
+No. Time Source Destination Protocol Length Info
+5 12.109000 192.168.2.254 192.168.1.254 ICMP 102 Echo (ping) request
+Frame 5: 102 bytes on wire (816 bits), 102 bytes captured (816 bits) on interface 0
+Ethernet II, Src: HuaweiTe_b1:15:3e (00:e0:fc:b1:15:3e), Dst: HuaweiTe_49:20:bb (00:e0:fc:49:20:bb)
+MultiProtocol Label Switching Header, Label: 1024, Exp: 0, S: 0, TTL: 254
+MultiProtocol Label Switching Header, Label: 1026, Exp: 0, S: 1, TTL: 254
+Internet Protocol Version 4, Src: 192.168.2.254, Dst: 192.168.1.254
+Internet Control Message Protocol
+```
+
+第二节:MPLS VPN部署与应用
+
+一:MPLS VPN应用与组网概述
+
+1.MPLS VPN典型应用
+
+目前,MPLS VPN的主要应用包括企业互连和虚拟业务网络
+
+ 企业互连应用:可通过MPLS VPN将分布在各地的分支机构和合作伙伴的IP网络连接在一起
+
+ 虚拟业务网络:可在同一物理网络上运行多种业务,如VoIP、IPTV等,为每个业务建立一个VPN,实现业务隔离
+
+
+
+**MPLS VPN的主要优点包括但不限于以下几项:**
+
+ 可以实现“一点接入,全网连通”,支持异种介质的互连。而不像传统专线那样在每一对用户设备间采用同样的介质连接,可方便地提供普遍服务
+
+ 可以实现“弹性带宽”,采用流量监管技术,在保证用户基本带宽的同时,对突发流量尽力而为,同时基本带宽也可以“软扩容”,即根据用户的需求在一个范围内连续选择
+
+ 在资源隔离或隧道绑定的MPLS VPN技术保证下,充分保证每个VPN的专有带宽,满足各类业务有不同的用户,不同的流量模型,不同的QoS要求
+
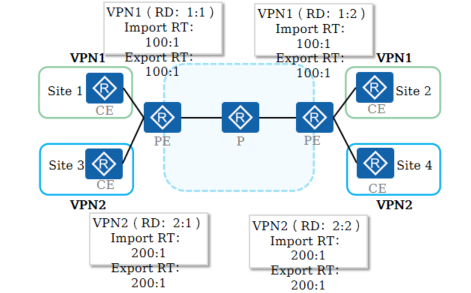
+2.MPLS VPN基本组网 - Intranet
+
+ 当采用Intranet组网方案时,一个VPN中的所有用户形成闭合用户群,相互之间能够进行流量转发,VPN中的用户不能与任何本VPN以外的用户通信,其站点通常是属于同一个组织
+
+
+
+ PE需要为每个站点创建VPN实例,并配置全网唯一的RD
+
+ PE通过配置Import RT和Export RT来控制不同VPN的站点做到无法互访
+
+3.MPLS VPN基本组网 - Extranet
+
+ 当采用Extranet组网方案时,VPN用户可将部分站点中的网络资源给其他VPN用户进行访问
+
+
+
+**如图,Site 2作为能被VPN1和VPN2访问的共享站点,需要保证:**
+
+ PE2能够接收PE1和PE3发布的VPNv4路由
+
+ PE2发布的VPNv4路由能够被PE1和PE3接收
+
+ PE2不把从PE1接收的VPNv4路由发布给PE3,也不把从PE3接收的VPNv4路由发布给PE1
+
+4.MPLS VPN基本组网 - Hub&Spoke
+
+ 当采用Hub&Spoke方案时,可以将多个站点中的一个站点设置为Hub站点,其余站点为Spoke站点。站点间的互访必须通过Hub站点,通过Hub站点集中管控站点间的数据传输
+
+
+
+ Spoke站点需要把路由发布给Hub站点,再通过Hub站点发布给其他Spoke站点。Spoke站点之间不直接交互路由信息
+
+ Spoke-PE需要设置Export Target为“Spoke”,Import Target为“Hub”
+
+ Hub-PE上需要使用两个接口或子接口(创建两个VPN实例),一个用于接收Spoke-PE发来的路由,其VPN实例的Import Target为“Spoke”;另一个用于向Spoke-PE发布路由,其VPN实例的Export Target为“Hub”
+
+**从Site1到Site2的路由发布过程如下:**
+
+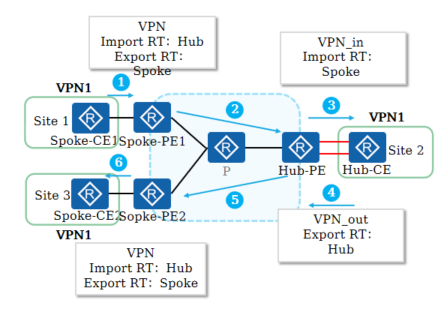
+
+ Spoke-CE1发布路由给Spoke-PE1
+
+ Spoke-PE1通过IBGP将该路由发布给Hub-PE
+
+ Hub-PE通过VPN实例(VPN_in)的Import Target属性将该路由引入VPN_in路由表,并发布给Hub-CE
+
+ Hub-CE学习到该路由,并将该路由发布给Hub-PE的VPN实例(VPN_out)
+
+ Hub-PE通过VPN_out发布该路由给Spoke-PE2(携带VPN_out的Export Target属性)
+
+ Spoke-PE2该路由发布给Spoke-CE2
+
+5.MCE组网
+
+ 当一个私网需要根据业务或者网络划分VPN时,不同VPN用户间的业务需要完全隔离。此时,为每个VPN单独配置一台CE将增加用户的设备开支和维护成本
+
+ 具有MCE(Multi-VPN-Instance,CE多实例CE)功能的CE设备可以在MPLS VPN组网应用中承担多个VPN实例的CE功能,减少用户网络设备的投入
+
+
+
+ MCE将PE的部分功能扩展到CE设备,通过将不同的接口与VPN绑定,并为每个VPN创建和维护独立的路由转发表(Multi-VRF)
+
+ MCE与对应的PE之间可以通过物理接口、子接口或者逻辑接口进行互联,PE上需要将这些接口绑定到对应的VPN实例
+
+6.MPLS VPN跨域组网
+
+ 随着MPLS VPN解决方案的广泛应用,服务的终端用户的规格和范围也在增长,在一个企业内部的站点数目越来越大,某个地理位置与另外一个服务提供商相连的需求变得非常的普遍,例如国内运营商的不同城域网之间,或相互协作的运营商的骨干网之间都存在着跨越不同自治系统(AS,Autonomous System)的情况
+
+ 一般的MPLS VPN体系结构都是在一个AS内运行,任何VPN的路由信息都是只能在一个AS内按需扩散。AS之间的MPLS VPN部署需要通过跨域(Inter-AS) MPLS VPN解决方案来实现
+
+
+
+**RFC2547中提出了三种跨域VPN解决方案,分别是:**
+
+ 跨域VPN-OptionA(Inter-Provider Backbones Option A)方式:需要跨域的VPN在ASBR(AS Boundary Router)间通过专用的接口管理自己的VPN路由,也称为VRF-to-VRF
+
+ 跨域VPN-OptionB(Inter-Provider Backbones Option B)方式:ASBR间通过MP-EBGP发布标签VPN-IPv4路由,也称为EBGP redistribution of labeled VPN-IPv4 routes
+
+ 跨域VPN-OptionC(Inter-Provider Backbones Option C)方式:PE间通过Multi-hop MP-EBGP发布标签VPN-IPv4路由,也称为Multihop EBGP redistribution of labeled VPN-IPv4 routes
+
+二:MPLS VPN典型场景部署介绍
+
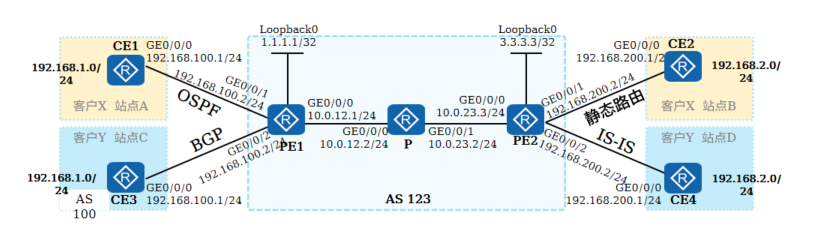
+1.部署Intranet场景的MPLS VPN
+
+ 如图所示,客户X及Y各自有2个站点,现需要通过MPLS VPN实现站点之间的互联,分别对应VPNX和VPNY
+
+ 互联接口、AS号及IP地址信息,CE与PE通过如图的协议或方法交换路由信息
+
+
+
+**部署思路**
+
+ MPLS VPN骨干网配置
+
+ IGP配置,实现骨干网的IP连通性
+
+ MPLS与MPLS LDP配置,建立MPLS LSP公网隧道,传输VPN数据
+
+ MP-BGP配置,建立后续传递VPNv4路由的MP-BGP对等体关系
+
+ VPN用户接入配置
+
+ 创建VPN实例并配置参数(RT、RD)
+
+ 将接口加入VPN实例
+
+ 配置PE与CE之间的路由交换
+
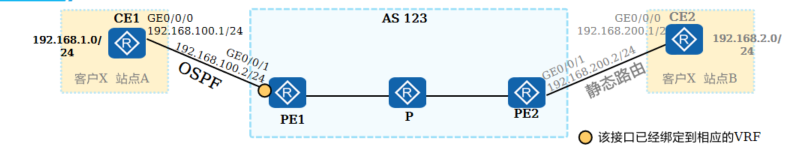
+**PE-CE之间部署OSPF **
+
+
+
+```shell
+[CE1] ospf 1
+[CE1-ospf-1] area 0
+[CE1-ospf-1-area-0.0.0.0] network 192.168.100.0 0.0.0.255
+[CE1-ospf-1-area-0.0.0.0] network 192.168.1.0 0.0.0.255
+```
+
+注意:
+
+ CE1的OSPF配置还是传统的OSPF配置,CE1无需支持VRF
+
+```shell
+[PE1] ospf 1 vpn-instance VPNX
+[PE1-ospf-1] area 0
+[PE1-ospf-1-area-0.0.0.0] network 192.168.100.0 0.0.0.255
+[PE1-ospf-1-area-0.0.0.0] quit
+[PE1-ospf-1] import bgp
+```
+
+注意:
+
+ PE1用于跟CE1对接的OSPF进程必须与对应的VPN实例绑定。将PE1的VPN实例VPNX的路由表中的BGP路由(主要是PE1通过BGP获知的、到达站点B的客户路由)引入OSPF,以便将这些路由通过OSPF通告给CE1。
+
+```shell
+[PE1] bgp 123
+[PE1-bgp] ipv4-family vpn-instance VPNX
+[PE1-bgp] import-route ospf 1
+```
+
+注意:
+
+ 将PE1的VPN实例VPNX的路由表中通过OSPF进程1学习到的OSPF路由引入BGP,从而将到达站点A的客户路由转换成BGP的VPNv4路由,以便通告给远端的PE2。
+
+**PE-CE之间部署静态路由**
+
+
+
+```shell
+[CE2] ip route-static 192.168.1.0 24 192.168.200.2
+[CE2] ip route-static 192.168.100.0 24 192.168.200.2
+```
+
+注意:
+
+ CE2需配置到达站点A内的各个网段的静态路由
+
+```shell
+[PE2] ip route-static vpn-instance VPNX 192.168.2.0 24 192.168.200.1
+```
+
+注意:
+
+ PE2需配置到达站点B内各个网段的静态路由
+
+```shell
+[PE2] bgp 123
+[PE2-bgp] ipv4-family vpn-instance VPNX
+[PE2-bgp] import-route static
+```
+
+注意:
+
+ 将PE2的VPN实例VPNX的路由表中的静态路由引入BGP,从而将客户路由转换成BGP的VPNv4路由,以便通告给远端的PE1
+
+**PE-CE之间部署EBGP**
+
+
+
+```shell
+[CE3] bgp 100
+[CE3-bgp] peer 192.168.100.2 as-number 123
+[CE3-bgp] network 192.168.1.0 24
+```
+
+注意:
+
+ CE3只需要执行普通BGP配置,且无需支持VRF。
+
+```shell
+[PE1] bgp 123
+[PE1-bgp] ipv4-family vpn-instance VPNY
+[PE1-bgp-VPNY] peer 192.168.100.1 as-number 100
+```
+
+注意:
+
+ 当PE与CE之间使用BGP交互客户路由时,无需在PE上手工执行路由重分发操作。在本例中,PE1通过BGP从CE3学习到的客户路由后,PE1会自动将这些路由转换成VPNv4路由并通告给PE2;而PE1通过BGP从PE2获知到达站点D的路由后,会自动将它们转换成IPv4路由并通告给CE3。
+
+**特殊场景下的BGP配置 - AS号替换**
+
+ 在MPLS VPN场景中,若PE与CE之间运行EBGP交互路由信息,则可能会出现两个站点的AS号相同的情况
+
+
+
+ 若CE1通过EBGP向PE1发送一条私网路由,并经过PE2发送到CE2,则CE2会由于AS号重复丢弃这条路由,导致属于同一VPN的Site 1和Site 2之间无法连通
+
+ 可以在PE上执行peer substitute-as命令使能AS号替换功能,即PE用本地AS号替换收到的私网路由中CE所在VPN站点的AS号,这样对端CE就不会因为AS号重复而丢弃路由了
+
+```shell
+[PE1] bgp 123
+[PE1-bgp] ipv4-family vpn-instance vpn1
+[PE1-bgp-vpn1] peer 192.168.100.1 substitute-as
+```
+
+ PE1在向CE1发送BGP路由时,若发现AS_Path中包含65001,则会用本地AS号,也就是123去替换65001。所以,若有一条路由从CE2传给PE2,再由PE2传给PE1,当PE1再传递给CE1,此时BGP路由的AS_Path属性为{123,123}
+
+**特殊场景下的BGP配置 - SoO**
+
+在CE多归属场景,若使能了BGP的AS号替换功能,可能会引起路由环路,需要SoO(Site of Origin)特性来避免环路
+
+ CE1与CE3处于同一个VPN站点1,CE2位于站点Site2,Site1和Site2站点所在的AS号都为65001。PE与CE之间运行的都是EBGP路由协议,为了Site 1和Site 2之间的路由可以正常学习,需要在PE1和PE2上配置AS号替换功能
+
+ CE1传递站点内的路由给PE1,PE1传递该路由给CE3,由于配置AS号替换,CE3会接收该路由,可能会导致产生路由环路
+
+```shell
+[PE1] bgp 123
+[PE1-bgp] ipv4-family vpn-instance vpn1
+[PE1-bgp-vpn1] peer 192.168.100.1 soo 200:1
+[PE1-bgp-vpn1] peer 192.168.200.1 soo 200:1
+```
+
+配置了BGP邻居的SoO后:
+
+ 接收到该邻居的BGP路由时,会在路径属性中携带该SoO属性并通告给其他BGP邻居
+
+ 向该邻居通告BGP路由时,会检查路由中的SoO属性是否与配置的SoO值相同,若相同则不通告,避免引起环路
+
+
+
+**PE-CE之间部署IS-IS**
+
+
+
+```shell
+[CE4] isis 1
+[CE4-isis-1] network-entity 49.0001.0000.0000.1111.00
+[CE4-isis-1] is-level level-2
+[CE4-isis-1] quit
+[CE4] interface GigabitEthernet 0/0/0
+[CE4-GigabitEthernet0/0/0] isis enable 1
+[CE4-GigabitEthernet0/0/0]quit
+[CE4] interface GigabitEthernet 0/0/1
+[CE4-GigabitEthernet0/0/1] isis enable 1
+#GE0/0/1接口是192.168.2.0/24网段所在接口
+```
+
+```shell
+[PE2] isis 1 vpn-instance VPNY
+[PE2-isis-1] network-entity 49.0002.0000.0000.2222.00
+[PE2-isis-1] is-level level-2
+[PE2-isis-1] import-route bgp level-2
+[PE2-isis-1] quit
+[PE2] interface GigabitEthernet 0/0/2
+[PE2-GigabitEthernet0/0/2] isis enable 1
+[PE2] bgp 123
+[PE2-bgp] ipv4-family vpn-instance VPNY
+[PE2-bgp] import-route isis 1
+```
diff --git a/MD/第十三章:大型WLAN组网部署.md b/MD/第十三章:大型WLAN组网部署.md
new file mode 100644
index 0000000..c13d500
--- /dev/null
+++ b/MD/第十三章:大型WLAN组网部署.md
@@ -0,0 +1,1173 @@
+大型WLAN组网部署
+
+> 作者:行癫
+
+------
+
+第一节:大型WLAN组网部署
+
+一:大型WLAN组网概述
+
+1.大型WLAN组网的应用
+
+ +
+
+
+2.大型WLAN组网特点
+
+**网络规模大**
+
+ 设备型号繁杂、分布位置广且设备数量庞大,运维成本高
+
+**用户多分布广**
+
+ 用户数量庞大,分布较广,网络体验要求高。
+
+**接入安全要求高**
+
+ 访客、员工、合作伙伴等人员会在不定期接入到内部网络,一个密码就能接入网络的场景不再适用。
+
+**可靠性要求高**
+
+ AC控制器掌控全网的无线网络,出现故障会带来极大的经济损失。
+
+3.华为大型WLAN方案功能
+
+**设备统一管理 **
+
+ 全网设备统一纳管,配置自动备份,告警实时上报,网管不再有烦恼。
+
+**漫游&业务随行**
+
+ 无缝漫游,用户在园区网络内移动时,只要身份不变,则其网络访问权限及体验将随之而动
+
+**接入&终端安全保障**'
+
+ '准入控制技术以及终端安全防护确保安全无死角。
+
+**高可靠性技术**
+
+ 双机冷备、双机热备、N+1备份等多种高可靠性技术保障WLAN网络稳定运行。
+
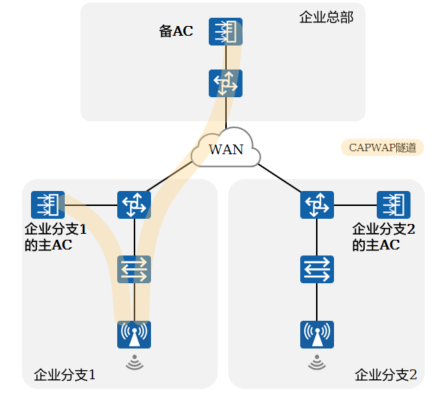
+4.WLAN网络解决方案
+
+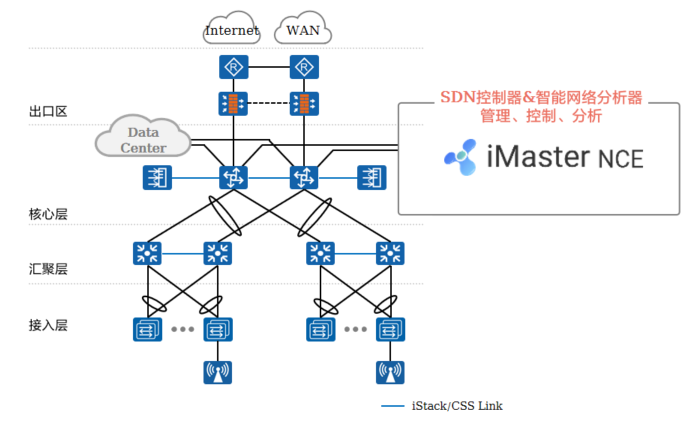 +
+ WLAN配合SDN控制器使用,由SDN控制器统一管理和配置,能够实现业务发放自动化、网络全生命周期管理,结合大数据和AI技术可实现园区网络的智能、极简和安全。园区网络更具备有线与无线的深度融合能力
+
+
+
+ WLAN配合SDN控制器使用,由SDN控制器统一管理和配置,能够实现业务发放自动化、网络全生命周期管理,结合大数据和AI技术可实现园区网络的智能、极简和安全。园区网络更具备有线与无线的深度融合能力
+
+5.大型WLAN网络关键技术
+
+| **技术** | **作用** |
+| ------------------- | ------------------------------------------------------------ |
+| VLAN Pool | 通过VLAN Pool把接入的用户分配到不同的VLAN,可以减少广播域,减少网络中的广播报文,提升网络性能。 |
+| DHCP Option 43 & 52 | 当AC和AP间是三层组网时,AP通过发送广播请求报文的方式无法发现AC,这时需要通过DHCP服务器回应给AP的报文中携带的Option43字段(IPv4)或Option52(IPv6)来通告AC的IP地址。 |
+| 漫游技术 | WLAN漫游是指STA在不同AP覆盖范围之间移动且保持用户业务不中断的行为。 |
+| 高可靠性技术 | 为了保证WLAN业务的稳定运行,保证在主设备故障时业务能够顺利切换到备份设备的技术。 |
+| 准入控制 | 准入控制技术是通过对接入网络的客户端和用户的认证来保证网络的安全,是一种“端到端”的安全技术。 |
+
+二:VLAN Pool
+
+1.VLAN Pool 概念
+
+**现有网络面临的挑战**
+
+ 无线网络终端的移动性导致特定区域IP地址请求较多
+
+ 通过情况下,一个SSID只能对应一个业务VLAN,如果通过扩大子网增加IP地址则会导致广播域扩大,大量的广播报文造成网络拥塞
+
+
+
+ VLAN Pool是一种把多个VLAN放在一个池中并提供分配算法的VLAN分配技术,又称为VLAN池
+
+**注意:**
+
+ 通过VLAN Pool把接入的用户分配到不同的VLAN,可以减少广播域,减少网络中的广播报文,提升网络性能
+
+ 由于无线终端的移动性,在无线网络中经常有大量用户从某个区域接入后,随着用的移动,再漫游到其他区域,导致该区域的用户接入多,对IP地址数目要求大。比如:场馆入口、酒店的大堂等。目前一个SSID只能对应一个VLAN,一个VLAN对应一个子网,如果大量用户从某一区域接入,只能扩大VLAN的子网,保证用户能够获取到IP地址。这样带来的问题就是广播域扩大,导致大量的广播报文(如:ARP、DHCP等)带来严重的网络拥塞
+
+2.VLAN Pool分配VLAN的算法
+
+ 顺序分配算法:把用户按上线顺序依次划分到不同的VLAN中
+
+ HASH分配算法:根据用户MAC地址HASH值分配VLAN
+
+**两种分配方式的比较:**
+
+| **分配算法** | **优点** | **缺点** |
+| ------------ | ------------------------------------ | ---------------------------- |
+| 顺序分配 | 各个VLAN用户数目划分均匀 | 重新上线VLAN容易变更、IP变化 |
+| HASH分配 | 用户多次上线可分配相同的VLAN、IP不变 | 各个VLAN用户数划分不均衡 |
+
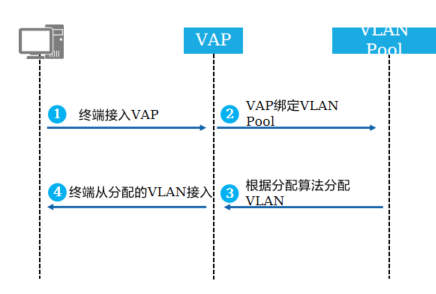
+3.分配VLAN流程
+
+
+
+ 用户终端从某个VAP接入,判断VAP是否有绑定VLAN Pool
+
+ 如果该VAP对应的模板绑定了VLAN Pool,使用VLAN Pool的分配算法分配一个VLAN, VLAN Pool有顺序分配和hash分配两种分配算法
+
+ 给终端分配一个VLAN
+
+ 终端从VLAN Pool分配的VLAN上线
+
+**注意:**
+
+ 虚拟接入点VAP(Virtual Access Point):VAP就是在一个物理实体AP上虚拟出多个AP,每一个被虚拟出的AP就是一个VAP,每个VAP提供和物理实体AP一样的功能。用户可以在一个AP上创建不同的VAP来为不同的用户群体提供无线接入服务
+
+5.VLAN Pool应用示例
+
+
+
+6.配置介绍
+
+
+
+7.配置案例
+
+
+
+ AC是STA的DHCP服务器,已开启DHCP功能
+
+ DHCP服务器地址包含两个网段,分别为10.1.2.0/24以及10.1.3.0/24
+
+ DHCP客户机能够动态获取服务器分配的IP地址,IP地址池地址范围为10.1.2.0以及10.1.3.0网段地址,且网关地址为10.1.2.254, 10.1.3.254
+
+**AC的VLAN Pool配置如下:**
+
+```shell
+[AC] vlan pool STA
+[AC-vlan-pool-STA] vlan 20 30
+[AC-vlan-pool-STA] assignment hash
+[AC-vlan-pool-STA] quit
+```
+
+```shell
+[AC] wlan
+[AC-wlan-view] vap-profile name huawei
+[AC-wlan-vap-prof-huawei] service-vlan vlan-pool STA
+Info: This operation may take a few seconds, please wait. Done.
+```
+
+**在AC上查看所有VLAN pool下的简要配置信息:**
+
+```shell
+ display vlan pool all
+--------------------------------------------------------------------------------
+Name Assignment VLAN total
+--------------------------------------------------------------------------------
+STA hash 2
+--------------------------------------------------------------------------------
+Total: 2
+```
+
+**在AC上查看STA VLAN Pool下的详细配置信息:**
+
+```shell
+ display vlan pool name STA
+--------------------------------------------------------------------------------
+Name : STA
+Total : 2
+Assignment : hash
+VLAN ID : 20 30
+```
+
+三:DHCP技术
+
+1.DHCP中继
+
+ DHCP客户端使用IP广播来寻找同一网段上的DHCP服务器。当服务器和客户段处在不同网段,即被路由器分割开来时,路由器是不会转发这样的广播包
+
+ DHCP中继能够跨网段“透传”DHCP报文,使得一个DHCP服务器同时为多个网段服务成为可能
+
+
+
+ 随着网络规模的不断扩大,网络设备不断增多,企业内不同的用户可能分布在不同的网段,一台DHCP服务器在正常情况下无法满足多个网段的地址分配需求。企业内网各个网段通常都没有与DHCP Server在同一个二层广播域内,如果还需要通过DHCP服务器分配IP地址,则需要跨网段发送DHCP协议报文
+
+ 2.配置介绍
+
+
+
+3.配置案例
+
+
+
+ WLAN的管理VLAN是VLAN 10,AP通过DHCP获取IP地址
+
+ 在SW、AC和AR上配置基础互通参数
+
+ 将AP、AC和AR分别配置为DHCP的客户端、DHCP中继以及DHCP服务器,开启DHCP功能
+
+ AC上开启DHCP Relay功能,并且指定DHCP Server的IP地址为172.21.1.2
+
+ 在AR上创建地址池“AP”,地址范围为10.1.1.0/24,网关为10.1.1.2
+
+**SW和AC的配置如下:**
+
+```shell
+[SW] vlan 10
+[SW-vlan10] quit
+[SW] interface GigabitEthernet 0/0/1
+[SW-GigabitEthernet0/0/1] port link-type access
+[SW-GigabitEthernet0/0/1] port default vlan 10
+[SW-GigabitEthernet0/0/1] quit
+[SW] interface GigabitEthernet 0/0/2
+[SW-GigabitEthernet0/0/2] port link-type trunk
+[SW-GigabitEthernet0/0/2] port trunk allow-pass vlan 10
+[SW-GigabitEthernet0/0/2] quit
+[SW] interface Vlanif 10
+[SW-Vlanif10] ip address 10.1.1.1 24
+```
+
+```shell
+[AC] vlan batch 10 20
+[AC] interface GigabitEthernet 0/0/1
+[AC-GigabitEthernet0/0/1] port link-type trunk
+[AC-GigabitEthernet0/0/1] port trunk allow-pass vlan 10
+[AC-GigabitEthernet0/0/1] quit
+[AC] interface GigabitEthernet 0/0/2
+[AC-GigabitEthernet0/0/1] port link-type access
+[AC-GigabitEthernet0/0/1] port default vlan 20
+```
+
+**AC和AR的配置如下:**
+
+```shell
+[AC] interface Vlanif 10
+[AC-Vlanif10] ip address 10.1.1.2 24
+[AC-Vlanif10] quit
+[AC] interface Vlanif 20
+[AC-Vlanif20] ip address 172.21.1.1 24
+[AC-Vlanif20] quit
+```
+
+```shell
+[AR] interface GigabitEthernet 0/0/1
+[AR-GigabitEthernet0/0/1] ip address 172.21.1.2 24
+[AR-GigabitEthernet0/0/1] quit
+```
+
+```shell
+[AC] dhcp server group AP
+[AC-dhcp-server-group-AP] dhcp-server 172.21.1.2
+[AC-dhcp-server-group-AP] quit
+[AC] interface Vlanif 10
+[AC-Vlanif10] dhcp select relay
+[AC-Vlanif10] dhcp relay server-select AP
+[AC-Vlanif10] quit
+```
+
+**AR的配置如下:**
+
+```shell
+[AR] ip pool AP
+[AR-ip-pool-AP] network 10.1.1.0 mask 24
+[AR-ip-pool-AP] gateway-list 10.1.1.2
+[AR-ip-pool-AP] excluded-ip-address 10.1.1.1
+[AR-ip-pool-AP] quit
+[AR] interface GigabitEthernet 0/0/1
+[AR-GigabitEthernet0/0/1] dhcp select global
+[AR-GigabitEthernet0/0/1] quit
+[AR] ip route-static 10.1.1.0 255.255.255.0 172.21.1.1
+```
+
+**在AR上查看DHCP地址池分配情况:**
+
+```shell
+[AR] display ip pool name AP used
+……
+Network section :
+ ----------------------------------------------------------------------
+ Index IP MAC Lease Status
+ ----------------------------------------------------------------------
+ 253 10.1.1.254 00e0-fcca-1150 2181 Used
+ ----------------------------------------------------------------------
+[AR]
+```
+
+**在AC上查看DHCP Relay信息:**
+
+```shell
+ display dhcp relay all
+ DHCP relay agent running information of interface Vlanif10 :
+ Server group name : AP
+ Gateway address in use : 10.1.1.2
+```
+
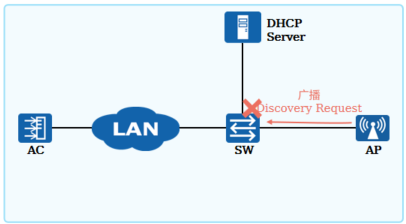
+4.WLAN三层组网AC发现机制
+
+ 当AC和AP间是三层组网时,AP通过发送广播请求报文的方式无法发现AC,这时需要通过DHCP服务器回应给AP的报文中携带的Option43字段(IPv4)或Option52(IPv6)来通告AC的IP地址
+
+
+
+ WLAN三层组网场景,AP的广播Discovery Request报文无法发现AC,导致CAPWAP隧道无法建立
+
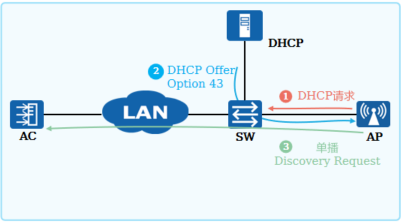
+
+
+ WLAN三层组网场景,配置DHCP Option 43后,在AP获取IP地址阶段,同时获取了AC的IP地址,直接通过单播与AC建立联系
+
+**配置介绍**
+
+
+
+**配置案例**
+
+
+
+ WLAN的管理VLAN是VLAN 10,AP通过DHCP获取IP地址
+
+ SW、AC以及AR的基础配置及DHCP Relay配置均已完成,AP能够正常获取到IP地址10.1.1.254,AC的IP地址为100.100.100.100
+
+ 在AR上创建地址池“AP”,地址范围为10.1.1.0/24,网关为10.1.1.2,并添加静态路由,确保AR能够访问到10.1.1.0网段
+
+**AR和AC配置如下:**
+
+```shell
+[AR] ip pool AP
+[AR-ip-pool-ap] option 43 sub-option 3 ascii 100.100.100.100
+[AR-ip-pool-ap] quit
+```
+
+```shell
+[AC] interface LoopBack 0
+[AC-LoopBack0] ip address 100.100.100.100 32
+[AC-LoopBack0] quit
+[AC] capwap source interface LoopBack 0
+```
+
+**在AR上查看DHCP地址池的配置情况:**
+
+```shell
+[AR] display ip pool name AP
+Pool-name : AP
+ Pool-No : 0
+ Lease : 1 Days 0 Hours 0 Minutes
+ Option-code : 43
+ Option-subcode : 3
+ Option-type : ascii
+ Option-value : 100.100.100.100
+……
+ Position : Local Status : Unlocked
+ Gateway-0 : 10.1.1.2
+ Mask : 255.255.255.0
+……
+```
+
+**在AC上查看AP能否正常发现AP**
+
+ 可以看到AP已经成功发现AC,在AC上可以随时将AP添加到AC上
+
+```shell
+[AC] display ap unauthorized record
+Unauthorized AP record:
+Total number: 1
+-----------------------------------------------------------------------------
+AP type: AP4030TN
+AP SN: 210235448310C92A877C
+AP MAC address: 00e0-fcca-1150
+AP IP address: 10.1.1.254
+Record time: 2020-06-18 11:51:34
+------------------------------------------------------------------------------
+[AC]
+```
+
+四:漫游技术
+
+1.WLAN漫游概述
+
+ +
+ WLAN漫游是指STA在不同AP覆盖范围之间移动且保持用户业务不中断的行为
+
+ 实现WLAN漫游的两个AP必须使用相同的SSID和安全模板(安全模板名称可以不同,但是安全模板下的配置必须相同),认证模板的认证方式和认证参数也要配置相同
+
+**WLAN漫游策略主要解决以下问题:**
+
+ 避免漫游过程中的认证时间过长导致丢包甚至业务中断
+
+ 保证用户授权信息不变
+
+ 保证用户IP地址不变
+
+
+
+ WLAN漫游是指STA在不同AP覆盖范围之间移动且保持用户业务不中断的行为
+
+ 实现WLAN漫游的两个AP必须使用相同的SSID和安全模板(安全模板名称可以不同,但是安全模板下的配置必须相同),认证模板的认证方式和认证参数也要配置相同
+
+**WLAN漫游策略主要解决以下问题:**
+
+ 避免漫游过程中的认证时间过长导致丢包甚至业务中断
+
+ 保证用户授权信息不变
+
+ 保证用户IP地址不变
+
+2.WLAN漫游的相关术语
+
+
+
+ AC内漫游:如果漫游过程中关联的是同一个AC,这次漫游就是AC内漫游
+
+ AC间漫游:如果漫游过程中关联的不是同一个AC,这次漫游就是AC间漫游
+
+ AC间隧道:为了支持AC间漫游,漫游组内的所有AC需要同步每个AC管理的STA和AP设备的信息,因此在AC间建立一条隧道作为数据同步和报文转发的通道。AC间隧道也是利用CAPWAP协议创建的。如图所示,AC1和AC2间建立AC间隧道进行数据同步和报文转发
+
+3.WLAN漫游类型
+
+
+
+ 二层漫游:1个无线客户端在2个AP(或多个AP)之间来回切换连接无线,前提是这些AP都绑定的是同1个SSID并且业务VLAN都在同1个VLAN内(在同一个IP地址段),漫游切换的过程中,无线客户端的接入属性(比如无线客户端所属的业务VLAN、获取的IP地址等属性)不会有任何变化,直接平滑过渡,在漫游的过程中不会有丢包和断线重连的现象
+
+ 三层漫游:漫游前后SSID的业务VLAN不同,AP所提供的业务网络为不同的三层网络,对应不同的网关。此时,为保持漫游用户IP地址不变的特性,需要将用户流量迂回到初始接入网段的AP,实现跨VLAN漫游
+
+4.WLAN漫游流量转发模型
+
+| **转发模型** | **特点** |
+| ---------------- | ------------------------------------------------------------ |
+| 二层漫游直接转发 | 由于二层漫游后STA仍然在原来的子网中,所以FAP/FAC对二层漫游用户的流量转发和平台新上线的用户没有区别,直接在FAP/FAC本地的网络转发,不需要通过隧道转发回家乡代理中转。 |
+| 二层漫游隧道转发 | |
+| 三层漫游直接转发 | HAP和HAC之间的业务报文不通过CAPWAP隧道封装,无法判定HAP和HAC是否在同一个子网内,此时设备默认报文需返回到HAP进行中转。 |
+| 三层漫游隧道转发 | HAP和HAC之间的业务报文通过CAPWAP隧道封装,此时可以将HAP和HAC看作在同一个子网内,所以报文无需返回HAP,可直接通过HAC中转到上层网络。 |
+
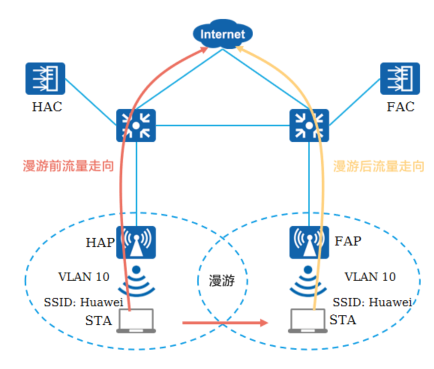
+5.AC间二层漫游 - 直接转发
+
+
+
+**漫游前:**
+
+ STA发送业务报文给HAP
+
+ HAP接收到业务报文后经由网关(交换机)发送给上层网络
+
+**漫游后:**
+
+ STA发送业务报文给FAP
+
+ FAP接收到业务报文后经由网关(交换机)发送给上层网络
+
+6.AC间三层漫游 - 隧道转发
+
+
+
+**漫游前:**
+
+ STA发送业务报文给HAP
+
+ HAP接收到业务报文后通过CAPWAP隧道发送给HAC
+
+ HAC直接将业务报文经过交换机发送给上层网络
+
+**漫游后:**
+
+ STA发送业务报文给FAP
+
+ FAP接收到业务报文后通过CAPWAP隧道发送给FAC
+
+ FAC通过HAC和FAC之间的AC间隧道将业务报文转发给HAC
+
+ HAC直接将业务报文经由交换机发送给上层网络
+
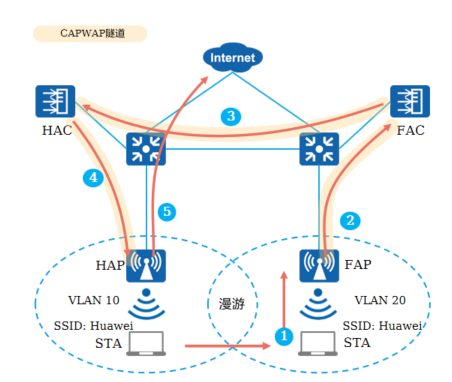
+7.AC间三层漫游 - 直接转发(HAP为家乡代理)
+
+
+
+**漫游前:**
+
+ STA发送业务报文给HAP
+
+ HAP接收到业务报文后直接将业务报文经过交换机发送给上层网络
+
+**漫游后:**
+
+ STA发送业务报文给FAP
+
+ FAP接收到STA发送的业务报文并通过CAPWAP隧道发送给FAC
+
+ FAC通过HAC和FAC之间的AC间隧道将业务报文转发给HAC
+
+ HAC通过CAPWAP隧道将业务报文发送给HAP
+
+ HAP直接将业务报文发送给上层网络
+
+8.AC间三层漫游 - 直接转发(HAC为家乡代理)
+
+
+
+**漫游前:**
+
+ STA发送业务报文给HAP
+
+ HAP接收到业务报文后直接将业务报文经过交换机发送给上层网络
+
+**漫游后:**
+
+ STA发送业务报文给FAP
+
+ FAP接收到STA发送的业务报文并通过CAPWAP隧道发送给FAC
+
+ FAC通过HAC和FAC之间的AC间隧道将业务报文转发给HAC
+
+ HAC直接将业务报文发送给上层网络
+
+9.AC间漫游配置介绍
+
+
+
+**配置漫游组**
+
+ 如果指定了漫游组服务器,则需要在漫游组服务器上配置漫游组
+
+ 如果没有指定漫游组服务器,则各成员AC均需配置漫游组
+
+10.配置案例
+
+
+
+ HAP与HAC,FAP与FAC之间的组网方式为三层组网
+
+ 配置HAC和FAC形成漫游组,保证STA的业务流量正常
+
+**配置AC1和AC2的WLAN漫游功能:**
+
+```shell
+[AC1-wlan-view] mobility-group name mobility
+[AC1-mc-mg-mobility] member ip-address 10.1.201.100
+[AC1-mc-mg-mobility] member ip-address 10.1.201.200
+[AC1-mc-mg-mobility] quit
+```
+
+```shell
+[AC2-wlan-view] mobility-group name mobility
+[AC2-mc-mg-mobility] member ip-address 10.1.201.100
+[AC2-mc-mg-mobility] member ip-address 10.1.201.200
+[AC2-mc-mg-mobility] quit
+```
+
+**STA漫游后在AC2上查看STA的漫游轨迹:**
+
+```shell
+ display station roam-track sta-mac 28b2-bd35-4af3
+Access SSID:huawei-guest1
+Rx/Tx: Rx-Rate/Tx-Rate Mbps
+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
+L2/L3 AC IP AP name Radio ID BSSID TIME In Rx/Tx RSSI Out Rx/Tx RSSI
+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
+ -- 10.1.201.100 ap1 1 cccc-8110-2250 2020/06/18 14:09:06 130/130 -44 130/130 -44
+ L3 10.1.201.200 ap2 1 cccc-8110-22b0 2020/06/18 14:12:24 130/6 -42 -/-
+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
+Number of roam track: 1
+```
+
+五:高可靠性技术
+
+1.AC高可靠性概述
+
+**在WLAN组网中,为保证组网可靠性,常见的备份技术有:**
+
+ VRRP双机热备份(主备)
+
+ 双链路冷备份
+
+ 双链路热备份(主备&负载分担)
+
+ N+1备份
+
+ 为了保证WLAN业务的稳定运行,热备份(Hot-Standby Backup)机制可以保证在主设备故障时业务能够不中断的顺利切换到备份设备
+
+**注意:**
+
+ 热备份是指,当两台设备在确定主用(Master)设备和备用(Backup)设备后,由主用设备进行业务的转发,而备用设备处于监控状态,同时主用设备实时向备用设备发送状态信息和需要备份的信息,当主用设备出现故障后,备用设备及时接替主用设备的业务运行
+
+**VRRP双机热备份**
+
+ 主备AC两个独立的IP地址,通过VRRP对外虚拟为同一个IP地址,单个AP和虚拟IP建立一条CAPWAP链路
+
+ 主AC备份AP信息、STA信息和CAPWAP链路信息,并通过HSB主备服务将信息同步给备AC。主AC故障后,备AC直接接替工作
+
+**双链路热备份**
+
+ 单个AP分别和主备AC建立CAPWAP链路,一条主链路,一条备链路
+
+ 主AC仅备份STA信息,并通过HSB主备服务将信息同步给备AC。主AC故障后,AP切换到备链路上,备AC接替工作
+
+**双链路冷备份**
+
+ 单个AP分别和主备AC建立CAPWAP链路,一条主链路,一条备链路
+
+ AC不备份同步信息。主AC故障后,AP切换到备链路上,备AC接替工作
+
+**N+1备份**
+
+ 单个AP只和一个AC建立CAPWAP链路
+
+ AC不备份同步信息。主AC故障后,AP重新与备AC建链CAPWAP链路,备AC接替工作
+
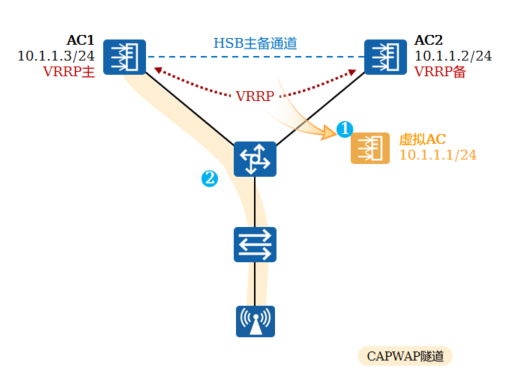
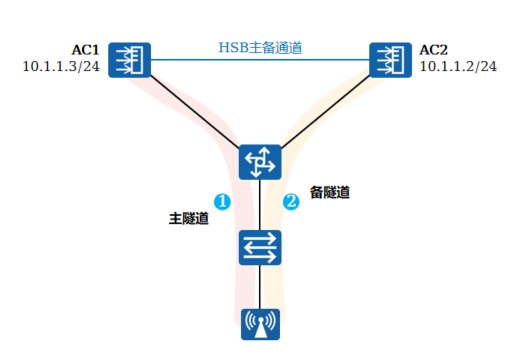
+2.VRRP双机热备
+
+
+
+ 两台AC组成一个VRRP组,主、备AC对AP始终显示为同一个虚拟IP地址,主AC通过Hot Standby(HSB)主备通道同步业务信息到备AC上
+
+ 两台AC通过VRRP协议产生一台“虚拟AC”,缺省情况下,主AC担任虚拟AC的具体工作,当主AC故障时,备AC接替其工作。所有AP与“虚拟AC”建立CAPWAP隧道
+
+ AP只看到一个AC的存在,AC间的切换由VRRP决定
+
+ 这种方式一般将主备AC部署在同一地理位置,和其他备份方式比较,其业务切换速度非常快
+
+**HSB相关概念**
+
+ HSB(Hot Standby,热备份)是华为主备公共机制
+
+ 主备服务(HSB service):建立和维护主备通道,为各个主备业务模块提供通道通断事件和报文发送/接收接口
+
+ 主备备份组(HSB group):HSB备份组内部绑定HSB service,为各个主备业务模块提供数据备份通道。HSB备份组与一个VRRP实例绑定,借用VRRP机制协商出主备实例。同时,HSB备份组还负责通知各个业务模块处理批量备份、实时备份、主备切换等事件
+
+**HSB主备服务**
+
+ HSB主备服务负责在两个互为备份的设备间建立主备备份通道,维护主备通道的链路状态,为其他业务提供报文的收发服务,并在备份链路发生故障时通知主备业务备份组进行相应的处理
+
+HSB主备服务主要包括两个方面:
+
+ 建立主备备份通道
+
+ 维护主备通道的链路状态
+
+**数据同步**
+
+ 基于VRRP双机热备备份信息包括用户表项、CAPWAP链路信息以及AP表项等信息,备份的方式有实时备份,批量备份,定时备份
+
+ 批量备份:主用设备会将已有的会话表项一次性同步到新加入的备份设备上,使主备AC信息对齐,这个过程称为批量备份。批量备份会在AC主备确立时进行触发
+
+ 实时备份:主用设备在产生新表项或表项变化后会及时备份到备份设备上
+
+ 定时同步:备用设备会每隔30分钟检查其已有的会话表项与主用设备是否一致,若不一致则将主用设备上的会话表项同步到备用设备
+
+**VRRP双机热备配置流程**
+
+ +
+ 创建VRRP备份组并配置虚拟IP地址
+
+ 创建HSB主备服务,建立HSB主备备份通道的IP地址和端口号
+
+ 创建HSB备份组,配置HSB备份组绑定HSB主备服务、VRRP备份组、WLAN业务以及DHCP
+
+ 使能HSB备份组,HSB备份组使能后,对HSB备份组的相关配置才会生效
+
+ 检查VRRP热备份配置结果
+
+**配置介绍**
+
+
+
+
+
+
+
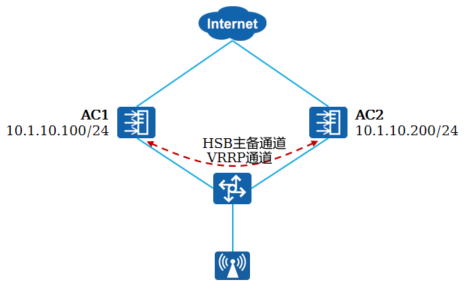
+**配置案例**
+
+
+
+ AC1和AC2通过VLANIF10建立VRRP主备关系,VRRP的虚拟IP为10.1.10.1,AC1为主设备,且优先级为120
+
+ 使用HSB技术实现双机热备
+
+AC的VRRP配置如下:
+
+```shell
+[AC1]interface Vlanif10
+[AC1-Vlanif10]ip address 10.1.10.100 255.255.255.0
+[AC1-Vlanif10]vrrp vrid 1 virtual-ip 10.1.10.1
+[AC1-Vlanif10]vrrp vrid 1 priority 120
+```
+
+```shell
+[AC2]interface Vlanif10
+[AC2-Vlanif10]ip address 10.1.10.200 255.255.255.0
+[AC2-Vlanif10]vrrp vrid 1 virtual-ip 10.1.10.1
+```
+
+AC的HSB配置如下:
+
+```shell
+[AC1]hsb-service 0
+[AC1-hsb-service-0]service-ip-port local-ip 10.1.10.100 peer-ip 10.1.10.200 local-data-port 10241 peer-data-port 10241
+[AC1-hsb-service-0]quit
+```
+
+```shell
+[AC1]hsb-group 0
+[AC1-hsb-group-0]bind-service 0
+[AC1-hsb-group-0]track vrrp vrid 1 interface Vlanif10
+[AC1-hsb-group-0]quit
+```
+
+```shell
+[AC1]hsb-service-type access-user hsb-group 0
+[AC1]hsb-service-type dhcp hsb-group 0
+[AC1]hsb-service-type ap hsb-group 0
+```
+
+```shell
+[AC1]hsb-group 0
+[AC1-hsb-group-0]hsb enable
+```
+
+**在AC上查看主备服务的建立情况**
+
+```shell
+[AC1] display hsb-service 0
+Hot Standby Service Information:
+----------------------------------------------------------
+ Local IP Address : 10.1.10.100
+ Peer IP Address : 10.1.10.200
+ Source Port : 10241
+ Destination Port : 10241
+ Keep Alive Times : 2
+ Keep Alive Interval : 1
+ Service State : Connected
+ Service Batch Modules :
+ Shared-key : -
+----------------------------------------------------------
+```
+
+**在AC上查看HSB备份组的运行情况**
+
+```shell
+[AC1] display hsb-group 0
+Hot Standby Group Information:
+----------------------------------------------------------
+ HSB-group ID : 0
+ Vrrp Group ID : 1
+ Vrrp Interface : Vlanif10
+ Service Index : 0
+ Group Vrrp Status : Master
+ Group Status : Active
+ Group Backup Process : Realtime
+ Peer Group Device Name : AirEngine 9700-M
+ Peer Group Software Version : V200R019C00
+ Group Backup Modules : Access-user
+ DHCP
+ AP
+```
+
+
+
+ 创建VRRP备份组并配置虚拟IP地址
+
+ 创建HSB主备服务,建立HSB主备备份通道的IP地址和端口号
+
+ 创建HSB备份组,配置HSB备份组绑定HSB主备服务、VRRP备份组、WLAN业务以及DHCP
+
+ 使能HSB备份组,HSB备份组使能后,对HSB备份组的相关配置才会生效
+
+ 检查VRRP热备份配置结果
+
+**配置介绍**
+
+
+
+
+
+
+
+**配置案例**
+
+
+
+ AC1和AC2通过VLANIF10建立VRRP主备关系,VRRP的虚拟IP为10.1.10.1,AC1为主设备,且优先级为120
+
+ 使用HSB技术实现双机热备
+
+AC的VRRP配置如下:
+
+```shell
+[AC1]interface Vlanif10
+[AC1-Vlanif10]ip address 10.1.10.100 255.255.255.0
+[AC1-Vlanif10]vrrp vrid 1 virtual-ip 10.1.10.1
+[AC1-Vlanif10]vrrp vrid 1 priority 120
+```
+
+```shell
+[AC2]interface Vlanif10
+[AC2-Vlanif10]ip address 10.1.10.200 255.255.255.0
+[AC2-Vlanif10]vrrp vrid 1 virtual-ip 10.1.10.1
+```
+
+AC的HSB配置如下:
+
+```shell
+[AC1]hsb-service 0
+[AC1-hsb-service-0]service-ip-port local-ip 10.1.10.100 peer-ip 10.1.10.200 local-data-port 10241 peer-data-port 10241
+[AC1-hsb-service-0]quit
+```
+
+```shell
+[AC1]hsb-group 0
+[AC1-hsb-group-0]bind-service 0
+[AC1-hsb-group-0]track vrrp vrid 1 interface Vlanif10
+[AC1-hsb-group-0]quit
+```
+
+```shell
+[AC1]hsb-service-type access-user hsb-group 0
+[AC1]hsb-service-type dhcp hsb-group 0
+[AC1]hsb-service-type ap hsb-group 0
+```
+
+```shell
+[AC1]hsb-group 0
+[AC1-hsb-group-0]hsb enable
+```
+
+**在AC上查看主备服务的建立情况**
+
+```shell
+[AC1] display hsb-service 0
+Hot Standby Service Information:
+----------------------------------------------------------
+ Local IP Address : 10.1.10.100
+ Peer IP Address : 10.1.10.200
+ Source Port : 10241
+ Destination Port : 10241
+ Keep Alive Times : 2
+ Keep Alive Interval : 1
+ Service State : Connected
+ Service Batch Modules :
+ Shared-key : -
+----------------------------------------------------------
+```
+
+**在AC上查看HSB备份组的运行情况**
+
+```shell
+[AC1] display hsb-group 0
+Hot Standby Group Information:
+----------------------------------------------------------
+ HSB-group ID : 0
+ Vrrp Group ID : 1
+ Vrrp Interface : Vlanif10
+ Service Index : 0
+ Group Vrrp Status : Master
+ Group Status : Active
+ Group Backup Process : Realtime
+ Peer Group Device Name : AirEngine 9700-M
+ Peer Group Software Version : V200R019C00
+ Group Backup Modules : Access-user
+ DHCP
+ AP
+```
+
+3.双链路双机热备
+
+
+
+ 双链路双机热备场景下,业务直接绑定HSB备份服务,这样HSB对业务仅提供备份数据收发的功能,用户的主备状态由双链路机制进行维护
+
+ AP同时与主备AC之间分别建立CAPWAP隧道,AC间的业务信息通过HSB主备通道同步
+
+ 当AP和主AC间链路断开,AP会通知备AC切换成主AC
+
+**主备协商&建立主链路**
+
+ +
+**AP与AC建立主链路,在Discovery阶段要优选出主AC**
+
+ 使能双链路备份功能后,AP开始发送Discovery Request报文
+
+ AC收到Request报文后回应Discovery Response报文
+
+ AP收集到主备AC回应的Discovery Response报文后,根据AC的优先级、设备的负载情况以及AC的IP地址来选择主AC
+
+ AP开始与优选出的主AC建立CAPWAP主链路
+
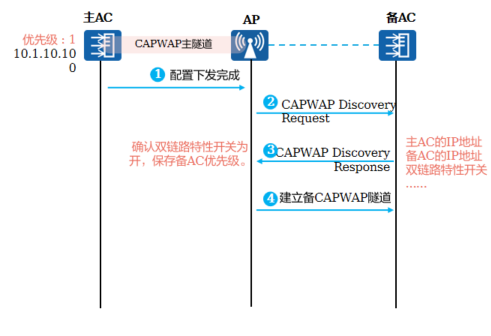
+**建立备链路**
+
+
+
+ AP与AC建立备链路,为了避免业务配置重复下发导致错误,在AP和 主AC建立主隧道并且配置下发完成后,才启动备CAPWAP链路的建立
+
+ 主AC下发配置到AP上
+
+ AP开始建立备用隧道,向备AC发送单播CAPWAP Discovery Request报文
+
+ 备AC收到Request报文后,回应Response报文,在该报文中携带优选AC的IP地址、备选AC的IP地址、双链路特性开关、负载情况及其优先级
+
+ AP收到备AC回应的Response报文后,获取到双链路特性开关为打开,并保存其优先级
+
+**配置介绍**
+
+
+
+
+
+**配置案例 **
+
+
+
+ AC1和AC2配置双链路双机热备,AC1为主设备,优先级为1,AC2为备设备,优先级为2
+
+ 使用HSB技术实现双机热备
+
+AC1的配置如下:
+
+```
+[AC1] wlan
+[AC1-wlan-view] ac protect enable
+[AC1-wlan-view] ac protect protect-ac 10.1.10.200 priority 1
+```
+
+```
+[AC1] hsb-service 0
+[AC1-hsb-service-0] service-ip-port local-ip 10.1.10.100 peer-ip 10.1.10.200 local-data-port 10241 peer-data-port 10241
+[AC1-hsb-service-0] quit
+```
+
+```
+[AC1] hsb-service-type access-user hsb-group 0
+[AC1] hsb-service-type dhcp hsb-group 0
+[AC1] hsb-service-type ap hsb-group 0
+```
+
+AC2的配置如下:
+
+```
+[AC2] wlan
+[AC2-wlan-view] ac protect enable
+[AC2-wlan-view] ac protect protect-ac 10.1.10.100 priority 2
+```
+
+```
+[AC2] hsb-service 0
+[AC2-hsb-service-0] service-ip-port local-ip 10.1.10.200 peer-ip 10.1.10.100 local-data-port 10241 peer-data-port 10241
+[AC2-hsb-service-0] quit
+```
+
+```
+[AC2] hsb-service-type access-user hsb-group 0
+[AC2] hsb-service-type dhcp hsb-group 0
+[AC2] hsb-service-type ap hsb-group 0
+```
+
+**在AC上查看双链路备份的配置信息**
+
+```
+[AC1] display ac protect
+------------------------------------------------------------
+Protect state : enable
+Protect AC IPv4 : 10.1.10.200
+Protect AC IPv6 : -
+Priority : 0
+Protect restore : enable
+...
+```
+
+**在AC上查看主备服务的建立情况**
+
+```
+[AC1] display hsb-service 0
+Hot Standby Service Information:
+----------------------------------------------------------
+ Local IP Address : 10.1.10.100
+ Peer IP Address : 10.1.10.200
+ Source Port : 10241
+ Destination Port : 10241
+ Keep Alive Times : 5
+ Keep Alive Interval : 3
+ Service State : Connected
+ Service Batch Modules : AP
+ Access-user
+ DHCP
+……
+```
+
+
+
+**AP与AC建立主链路,在Discovery阶段要优选出主AC**
+
+ 使能双链路备份功能后,AP开始发送Discovery Request报文
+
+ AC收到Request报文后回应Discovery Response报文
+
+ AP收集到主备AC回应的Discovery Response报文后,根据AC的优先级、设备的负载情况以及AC的IP地址来选择主AC
+
+ AP开始与优选出的主AC建立CAPWAP主链路
+
+**建立备链路**
+
+
+
+ AP与AC建立备链路,为了避免业务配置重复下发导致错误,在AP和 主AC建立主隧道并且配置下发完成后,才启动备CAPWAP链路的建立
+
+ 主AC下发配置到AP上
+
+ AP开始建立备用隧道,向备AC发送单播CAPWAP Discovery Request报文
+
+ 备AC收到Request报文后,回应Response报文,在该报文中携带优选AC的IP地址、备选AC的IP地址、双链路特性开关、负载情况及其优先级
+
+ AP收到备AC回应的Response报文后,获取到双链路特性开关为打开,并保存其优先级
+
+**配置介绍**
+
+
+
+
+
+**配置案例 **
+
+
+
+ AC1和AC2配置双链路双机热备,AC1为主设备,优先级为1,AC2为备设备,优先级为2
+
+ 使用HSB技术实现双机热备
+
+AC1的配置如下:
+
+```
+[AC1] wlan
+[AC1-wlan-view] ac protect enable
+[AC1-wlan-view] ac protect protect-ac 10.1.10.200 priority 1
+```
+
+```
+[AC1] hsb-service 0
+[AC1-hsb-service-0] service-ip-port local-ip 10.1.10.100 peer-ip 10.1.10.200 local-data-port 10241 peer-data-port 10241
+[AC1-hsb-service-0] quit
+```
+
+```
+[AC1] hsb-service-type access-user hsb-group 0
+[AC1] hsb-service-type dhcp hsb-group 0
+[AC1] hsb-service-type ap hsb-group 0
+```
+
+AC2的配置如下:
+
+```
+[AC2] wlan
+[AC2-wlan-view] ac protect enable
+[AC2-wlan-view] ac protect protect-ac 10.1.10.100 priority 2
+```
+
+```
+[AC2] hsb-service 0
+[AC2-hsb-service-0] service-ip-port local-ip 10.1.10.200 peer-ip 10.1.10.100 local-data-port 10241 peer-data-port 10241
+[AC2-hsb-service-0] quit
+```
+
+```
+[AC2] hsb-service-type access-user hsb-group 0
+[AC2] hsb-service-type dhcp hsb-group 0
+[AC2] hsb-service-type ap hsb-group 0
+```
+
+**在AC上查看双链路备份的配置信息**
+
+```
+[AC1] display ac protect
+------------------------------------------------------------
+Protect state : enable
+Protect AC IPv4 : 10.1.10.200
+Protect AC IPv6 : -
+Priority : 0
+Protect restore : enable
+...
+```
+
+**在AC上查看主备服务的建立情况**
+
+```
+[AC1] display hsb-service 0
+Hot Standby Service Information:
+----------------------------------------------------------
+ Local IP Address : 10.1.10.100
+ Peer IP Address : 10.1.10.200
+ Source Port : 10241
+ Destination Port : 10241
+ Keep Alive Times : 5
+ Keep Alive Interval : 3
+ Service State : Connected
+ Service Batch Modules : AP
+ Access-user
+ DHCP
+……
+```
+
+4.AC可靠性:N+1
+
+ +
+ N+1备份是指在AC+FIT AP的网络架构中,使用一台AC作为备AC,为多台主AC提供备份服务的一种解决方案
+
+ 网络正常情况下,AP只与各自所属的主AC建立CAPWAP链路
+
+ 当主AC故障或主AC与AP间CAPWAP链路故障时,备AC替代主AC来管理AP,备AC与AP间建立CAPWAP链路,为AP提供业务服务
+
+ 支持主备倒换,支持主备回切
+
+**N+1 备份—主备选择**
+
+
+
+ N+1备份是指在AC+FIT AP的网络架构中,使用一台AC作为备AC,为多台主AC提供备份服务的一种解决方案
+
+ 网络正常情况下,AP只与各自所属的主AC建立CAPWAP链路
+
+ 当主AC故障或主AC与AP间CAPWAP链路故障时,备AC替代主AC来管理AP,备AC与AP间建立CAPWAP链路,为AP提供业务服务
+
+ 支持主备倒换,支持主备回切
+
+**N+1 备份—主备选择**
+
+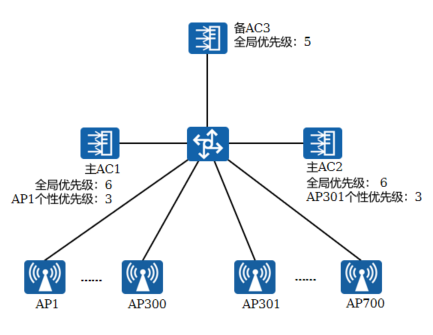 +
+ 在Discovery阶段,AP发现AC后,要选择出最高优先级的AC作为主AC接入
+
+AC上存在两种优先级:
+
+ 全局优先级:针对所有AP配置的AC优先级,默认为0,最大值为7,优先级取值越小,优先级越高
+
+ 个性优先级:针对指定的单个AP或指定AP组中的AP配置的AC优先级,没有默认值
+
+AC全局优先级六:准入控制技术
+
+
+
+ 在Discovery阶段,AP发现AC后,要选择出最高优先级的AC作为主AC接入
+
+AC上存在两种优先级:
+
+ 全局优先级:针对所有AP配置的AC优先级,默认为0,最大值为7,优先级取值越小,优先级越高
+
+ 个性优先级:针对指定的单个AP或指定AP组中的AP配置的AC优先级,没有默认值
+
+AC全局优先级六:准入控制技术
+
+1.NAC概述
+
+ NAC(Network Admission Control)称为网络接入控制,通过对接入网络的客户端和用户的认证保证网络的安全,是一种“端到端”的安全技术
+
+
+
+**NAC:**
+
+ 用于用户和接入设备之间的交互
+
+ NAC负责控制用户的接入方式(802.1X,MAC或Portal认证),接入过程中的各类参数和定时器
+
+ 确保合法用户和接入设备建立安全稳定的连接
+
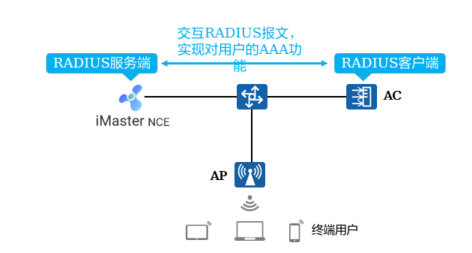
+2.RADIUS概述
+
+ AAA可以通过多种协议来实现,在实际应用中,最常使用RADIUS协议
+
+ RADIUS是一种分布式的、客户端/服务器结构的信息交互协议,能保护网络不受未授权访问的干扰,常应用在既要求较高安全性、又允许远程用户访问的各种网络环境中
+
+ 该协议定义了基于UDP(User Datagram Protocol)的RADIUS报文格式及其传输机制,并规定UDP端口1812、1813分别作为默认的认证、计费端口
+
+**RADIUS协议的主要特征如下:**
+
+ 客户端/服务器模式
+
+ 安全的消息交互机制
+
+ 良好的扩展性
+
+
+
+3.802.1X认证
+
+ 802.1X是IEEE制定的关于用户接入网络的认证标准,主要解决以太网内认证和安全方面的问题
+
+ 802.1X认证系统为典型的Client/Server结构,包括3个实体:请求方、认证方和认证服务器
+
+ 认证服务器通常是RADIUS服务器,用于对申请者进行认证、授权和计费
+
+ 对于大中型企业的员工,推荐使用802.1X认证
+
+
+
+4.MAC认证
+
+
+
+ MAC认证是一种基于MAC地址对用户的网络访问权限进行控制的认证方法,它不需要用户安装任何客户端软件
+
+ 接入设备在启动了MAC认证的接口上首次检测到用户的MAC地址后,即启动对该用户的认证操作
+
+ 认证过程中,不需要用户手动输入用户名或者密码
+
+ MAC认证常用于哑终端(如打印机)的接入认证,或者结合认证服务器完成MAC优先的Portal认证,用户首次认证通过后,一定时间内免认证再次接入
+
+5.Portal认证
+
+ Portal认证通常也称为Web认证,将浏览器作为认证客户端,不需要安装单独的认证客户端
+
+ 用户上网时,必须在Portal页面进行认证,只有认证通过后才可以使用网络资源,同时服务提供商可以在Portal页面上开展业务拓展,如展示商家广告等
+
+ 对于大中型企业的访客、商业会展和公共场所,推荐使用Portal认证
+
+**常用的Portal认证方式如下:**
+
+ 用户名和密码方式:由前台管理员给访客申请一个临时账号,访客使用临时账号认证
+
+ 短信认证:访客通过手机验证码方式认证
+
+
+
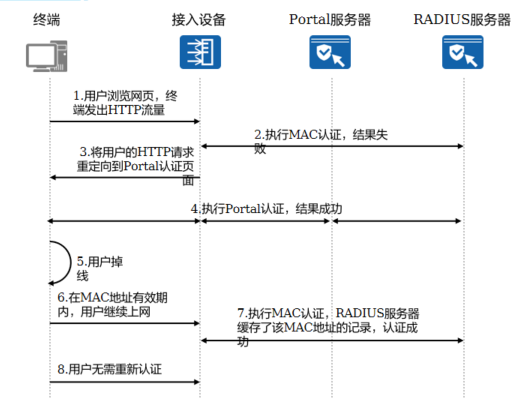
+6.MAC优先的Portal认证
+
+
+
+**技术背景**
+
+ 用户进行Portal认证成功后,如果断开网络,重新连接时需要再次输入用户名、密码,体验差。
+
+**MAC优先的Portal认证**
+
+ 用户进行Portal认证成功后,在一定时间内断开网络重新连接,能够直接通过MAC认证接入,无需输入用户名密码重新进行Portal**认证**
+
+ 该功能需要在设备配置MAC+Portal的混合认证,同时在认证服务器上开启MAC优先的Portal认证功能并配置MAC地址有效时间
+
+7.三种认证方式比较
+
+ NAC包括三种认证方式:802.1X认证、MAC认证和Portal认证。由于三种认证方式认证原理不同,各自适合的场景也有所差异,实际应用中,可以根据场景部署某一种合适的认证方式,也可以部署几种认证方式组成的混合认证,混合认证的组合方式以设备实际支持为准
+
+| **对比项** | **802.1X**认证 | **MAC**认证 | **Portal**认证 |
+| ---------- | ------------------------------------------ | ------------------------------------ | ---------------------------- |
+| 适合场景 | 新建网络、用户集中、信息安全要求严格的场景 | 打印机、传真机等哑终端接入认证的场景 | 用户分散、用户流动性大的场景 |
+| 客户端需求 | 需要 | 不需要 | 不需要 |
+| 优点 | 安全性高 | 无需安装客户端 | 部署灵活 |
+| 缺点 | 部署不灵活 | 需登记MAC地址,管理复杂 | 安全性不高 |
diff --git a/MD/第十二章:网络设备安全特性.md b/MD/第十二章:网络设备安全特性.md
new file mode 100644
index 0000000..5240a4e
--- /dev/null
+++ b/MD/第十二章:网络设备安全特性.md
@@ -0,0 +1,431 @@
+网络设备安全特性
+
+> 作者:行癫
+
+------
+
+第一节:网络设备安全特性
+
+一:常见设备安全加固策略
+
+1.为什么需要网络设备安全
+
+ +
+ 网络安全是一个系统工程,网络当中的每一样东西都有可能是被攻击的目标,网络设备本身当然也不例外
+
+**网络设备受到的常见攻击如下:**
+
+ 恶意登录网络设备执行非法操作,例如重启设备
+
+ 伪造大量控制报文造成设备CPU利用率升高,例如发送大量的ICMP报文
+
+
+
+ 网络安全是一个系统工程,网络当中的每一样东西都有可能是被攻击的目标,网络设备本身当然也不例外
+
+**网络设备受到的常见攻击如下:**
+
+ 恶意登录网络设备执行非法操作,例如重启设备
+
+ 伪造大量控制报文造成设备CPU利用率升高,例如发送大量的ICMP报文
+
+2.常见设备安全加固策略
+
+**常见的设备安全加固策略主要可以从以下方面部署:**
+
+ 关闭不使用的业务和协议端口
+
+ 废弃不安全的访问通道
+
+ 基于可信路径的访问控制
+
+ 本机防攻击
+
+**关闭不使用的业务和协议端口**
+
+ 在分析业务需求的基础上,按照最小授权原则,关闭不使用的业务和协议端口
+
+ 不使用的物理端口,应该默认配置为关闭,即使插上网线也不能通信
+
+ 不使用的协议端口,应该默认配置为关闭,不对外提供访问。如常见的telnet、FTP、HTTP等端口
+
+ +
+ 在SW1上关闭FTP功能,同时关闭多个不使用的端口
+
+```shell
+ system-view
+[SW1] undo ftp server
+Warning: The operation will stop the FTP server. Do you want to continue? [Y/N]:y
+Info: Succeeded in closing the FTP server.
+[SW1]port-group protgroup1
+[SW1-port-group-protgroup1]group-member GigabitEthernet 0/0/4 to GigabitEthernet0/0/48
+[SW1-port-group-protgroup1]shutdown
+```
+
+**废弃不安全的访问通道**
+
+ 在业务需求分析的基础上,优先满足业务的访问需求。在同一个访问需求有多种访问通道服务的情况下,废弃不安全的访问通道,而选择安全的访问通道
+
+| **访问需求** | **不安全的通道** | **安全的通道** |
+| ------------ | ---------------- | -------------- |
+| 远程登录 | Telnet | SSH v2 |
+| 文件传输 | FTP,TFTP | SFTP |
+| 网元管理 | SNMP v1/v2 | SNMP v3 |
+| 网管登录 | HTTP | HTTPS |
+
+ 通过命令行、WEB、网管等方式登录设备时,建议采用安全加密的通道SSH、HTTPS、SNMPv3
+
+ 设备之间,以及设备和终端之间数据传输,也建议采用加密的数据传输协议SFTP
+
+**安全的数据访问通道**
+
+设备数据传输安全常见场景及采用协议:
+
+ 用户远程登录:
+
+ Telnet:采用TCP协议进行明文传输
+
+ STelnet:基于SSH协议,提供安全的信息保障和强大的认证功能
+
+ 设备文件操作:
+
+ FTP:支持文件传输以及文件目录的操作,具有授权和认证功能,明文传输数据
+
+ TFTP:只支持文件传输,不支持授权和认证,明文传输数据
+
+ SFTP:支持文件传输及文件目录的操作,数据进行了严格加密和完整性保护
+
+**SSH概述**
+
+ SSH(Secure Shell,安全外壳协议),在非安全网络上提供了安全的远程登录、安全文件传输以及TCP/IP安全隧道。不仅在登陆过程中对密码进行加密传送,而且对登陆后执行的命令的数据也进行加密
+
+ 合法用户通过客户端登录,完成用户名以及对应的密码验证后,客户端会尝试和服务端建立会话,每个会话是一个独立的逻辑通道,可以提供给不同的上层应用使用
+
+ STelnet和SFTP各自利用了其中的一个逻辑通道,通过SSH对数据进行加密,从而实现数据的安全传输
+
+
+
+**SSH协议结构**
+
+
+
+ 在SW1上关闭FTP功能,同时关闭多个不使用的端口
+
+```shell
+ system-view
+[SW1] undo ftp server
+Warning: The operation will stop the FTP server. Do you want to continue? [Y/N]:y
+Info: Succeeded in closing the FTP server.
+[SW1]port-group protgroup1
+[SW1-port-group-protgroup1]group-member GigabitEthernet 0/0/4 to GigabitEthernet0/0/48
+[SW1-port-group-protgroup1]shutdown
+```
+
+**废弃不安全的访问通道**
+
+ 在业务需求分析的基础上,优先满足业务的访问需求。在同一个访问需求有多种访问通道服务的情况下,废弃不安全的访问通道,而选择安全的访问通道
+
+| **访问需求** | **不安全的通道** | **安全的通道** |
+| ------------ | ---------------- | -------------- |
+| 远程登录 | Telnet | SSH v2 |
+| 文件传输 | FTP,TFTP | SFTP |
+| 网元管理 | SNMP v1/v2 | SNMP v3 |
+| 网管登录 | HTTP | HTTPS |
+
+ 通过命令行、WEB、网管等方式登录设备时,建议采用安全加密的通道SSH、HTTPS、SNMPv3
+
+ 设备之间,以及设备和终端之间数据传输,也建议采用加密的数据传输协议SFTP
+
+**安全的数据访问通道**
+
+设备数据传输安全常见场景及采用协议:
+
+ 用户远程登录:
+
+ Telnet:采用TCP协议进行明文传输
+
+ STelnet:基于SSH协议,提供安全的信息保障和强大的认证功能
+
+ 设备文件操作:
+
+ FTP:支持文件传输以及文件目录的操作,具有授权和认证功能,明文传输数据
+
+ TFTP:只支持文件传输,不支持授权和认证,明文传输数据
+
+ SFTP:支持文件传输及文件目录的操作,数据进行了严格加密和完整性保护
+
+**SSH概述**
+
+ SSH(Secure Shell,安全外壳协议),在非安全网络上提供了安全的远程登录、安全文件传输以及TCP/IP安全隧道。不仅在登陆过程中对密码进行加密传送,而且对登陆后执行的命令的数据也进行加密
+
+ 合法用户通过客户端登录,完成用户名以及对应的密码验证后,客户端会尝试和服务端建立会话,每个会话是一个独立的逻辑通道,可以提供给不同的上层应用使用
+
+ STelnet和SFTP各自利用了其中的一个逻辑通道,通过SSH对数据进行加密,从而实现数据的安全传输
+
+
+
+**SSH协议结构**
+
+ +
+SSH协议框架中最主要的部分是三个协议:传输层协议、用户认证协议和连接协议:
+
+ 传输层协议:提供版本协商,加密算法协商,密钥交换,服务端认证以及信息完整性支持
+
+ 用户认证协议:为服务器提供客户端的身份鉴别
+
+ 连接协议:将加密的信息隧道复用为多个逻辑通道,提供给高层的应用协议(STelnet、SFTP)使用;各种高层应用协议可以相对地独立于SSH基本体系之外,并依靠这个基本框架,通过连接协议使用SSH的安全机制
+
+SSH中用到的算法主要有几类:
+
+ 用于数据完整性保护的MAC算法,如hmac-md5、hmac-md5-96等
+
+ 用于数据信息加密的算法,如3des-cbc、aes128-cbc、des-cbc等
+
+ 用于产生会话密钥的密钥交换算法,如diffle-hellman-group-exchange-sha1等
+
+ 用于进行数字签名和认证的主机公钥算法,如RSA、DSA等
+
+公开密钥技术:
+
+ 公钥加密算法也称非对称密钥算法,用两对密钥:一个公共密钥和一个专用密钥。用户要保障专用密钥的安全;公共密钥则可以发布出去。公共密钥与专用密钥是有紧密关系的,用公共密钥加密的信息只能用专用密钥解密,反之亦然。由于公钥算法不需要联机密钥服务器,密钥分配协议简单,所以极大简化了密钥管理。除加密功能外,公钥系统还可以提供数字签名
+
+ 机密性:指信息在存储、传输、使用的过程中,不会被泄漏给非授权用户或实体
+
+ 完整性:指信息在存储、传输、使用的过程中,不会被非授权用户篡改或防止授权用户对信息进行不恰当的篡改
+
+ 可用性:指确保授权用户或实体对信息资源的正常使用不会被异常拒绝,允许其可靠而及时地访问信息资源
+
+**基于可信路径的访问控制**
+
+ 可以在设备上部署基于可信路径的访问控制策略,以提升网络的安全性
+
+ 部署URPF,可以判定某个报文的源地址是否合法,如果该报文的路径与URPF学习的路径不符,丢弃该报文,用URPF可以有效防范IP地址欺骗
+
+
+
+ IP网络的开放性决定了,只要路由可达,任何人都可以对目标主机进行访问或者攻击
+
+ 对于某一个主机而言,访问它的客户端的报文历经的路径通常是固定的,尤其是在网络边缘,这种路径的固定特性表现得更加明显
+
+ URPF(单播逆向路径转发)分为严格模式和松散模式以及允许匹配缺省路由的方式。其原理是当设备转发IP报文时,检查数据报文的源IP地址是否合法,检查的原理是根据数据包的源IP地址查路由表
+
+**本机防攻击**
+
+ 在网络中,存在着大量针对CPU的恶意攻击报文以及需要正常上送CPU的各类报文。针对CPU的恶意攻击报文会导致CPU长时间繁忙的处理攻击报文,从而引发其他业务的断续甚至系统的中断;大量正常的报文也会导致CPU占用率过高,性能下降,从而影响正常的业务
+
+ 为了保护CPU,保证CPU对正常业务的处理和响应,设备提供了本机防攻击功能。本机防攻击针对的是上送CPU的报文,主要用于保护设备自身安全,保证已有业务在发生攻击时的正常运转,避免设备遭受攻击时各业务的相互影响
+
+本机防攻击包括CPU防攻击和攻击溯源两部分:
+
+ CPU防攻击针对上送CPU的报文进行限制和约束,使单位时间内上送CPU报文的数量限制在一定的范围之内,从而保护CPU的安全,保证CPU对业务的正常处理
+
+ 攻击溯源针对DoS(Denial of Service,拒绝服务)攻击进行防御。设备通过对上送CPU的报文进行分析统计,然后对统计的报文设置一定的阈值,将超过阈值的报文判定为攻击报文,再对这些攻击报文根据报文信息找出攻击源用户或者攻击源接口,最后通过日志、告警等方式提醒管理员以便管理员采用一定的措施来保护设备,或者直接丢弃攻击报文以对攻击源进行惩罚
+
+**CPU防攻击**
+
+多级安全机制,保证设备的安全,实现了对设备的分级保护。设备通过以下策略实现对设备的分级保护:
+
+ 第一级:通过黑名单来过滤上送CPU的非法报文
+
+ 第二级:CPCAR,对上送CPU的报文按照协议类型进行速率限制,保证每种协议上送CPU的报文不会过多
+
+ 第三级:对上送CPU的报文,按照协议优先级进行调度,保证优先级高的协议先得到处理
+
+ 第四级:对上送CPU的报文统一限速,对超过统一限速值的报文随机丢弃,保证整体上送CPU的报文不会过多,保护CPU安全
+
+ 动态链路保护功能的CPU报文限速,是指当设备检测到SSH Session数据、Telnet Session数据、HTTP Session数据、FTP Session数据以及BGP Session数据建立时,会启动对此Session的动态链路保护功能,后续上送报文如匹配此Session特征信息,此类数据将会享受高速率上送的权利,由此保证了此Session相关业务的运行可靠性、稳定性
+
+**攻击溯源原理 **
+
+ 攻击溯源包括报文解析、流量分析、攻击源识别和发送日志告警通知管理员以及实施惩罚四个过程
+
+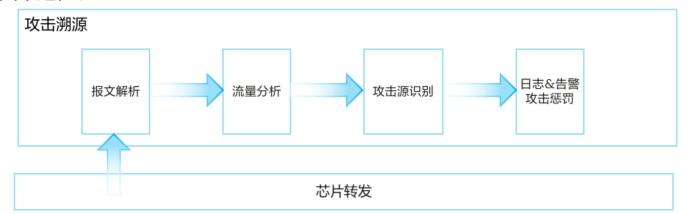
+
+ 通过图中所示的四个过程,找出攻击源,然后管理员通过ACL或配置黑名单的方式限制攻击源,以保护设备CPU
+
+
+
+SSH协议框架中最主要的部分是三个协议:传输层协议、用户认证协议和连接协议:
+
+ 传输层协议:提供版本协商,加密算法协商,密钥交换,服务端认证以及信息完整性支持
+
+ 用户认证协议:为服务器提供客户端的身份鉴别
+
+ 连接协议:将加密的信息隧道复用为多个逻辑通道,提供给高层的应用协议(STelnet、SFTP)使用;各种高层应用协议可以相对地独立于SSH基本体系之外,并依靠这个基本框架,通过连接协议使用SSH的安全机制
+
+SSH中用到的算法主要有几类:
+
+ 用于数据完整性保护的MAC算法,如hmac-md5、hmac-md5-96等
+
+ 用于数据信息加密的算法,如3des-cbc、aes128-cbc、des-cbc等
+
+ 用于产生会话密钥的密钥交换算法,如diffle-hellman-group-exchange-sha1等
+
+ 用于进行数字签名和认证的主机公钥算法,如RSA、DSA等
+
+公开密钥技术:
+
+ 公钥加密算法也称非对称密钥算法,用两对密钥:一个公共密钥和一个专用密钥。用户要保障专用密钥的安全;公共密钥则可以发布出去。公共密钥与专用密钥是有紧密关系的,用公共密钥加密的信息只能用专用密钥解密,反之亦然。由于公钥算法不需要联机密钥服务器,密钥分配协议简单,所以极大简化了密钥管理。除加密功能外,公钥系统还可以提供数字签名
+
+ 机密性:指信息在存储、传输、使用的过程中,不会被泄漏给非授权用户或实体
+
+ 完整性:指信息在存储、传输、使用的过程中,不会被非授权用户篡改或防止授权用户对信息进行不恰当的篡改
+
+ 可用性:指确保授权用户或实体对信息资源的正常使用不会被异常拒绝,允许其可靠而及时地访问信息资源
+
+**基于可信路径的访问控制**
+
+ 可以在设备上部署基于可信路径的访问控制策略,以提升网络的安全性
+
+ 部署URPF,可以判定某个报文的源地址是否合法,如果该报文的路径与URPF学习的路径不符,丢弃该报文,用URPF可以有效防范IP地址欺骗
+
+
+
+ IP网络的开放性决定了,只要路由可达,任何人都可以对目标主机进行访问或者攻击
+
+ 对于某一个主机而言,访问它的客户端的报文历经的路径通常是固定的,尤其是在网络边缘,这种路径的固定特性表现得更加明显
+
+ URPF(单播逆向路径转发)分为严格模式和松散模式以及允许匹配缺省路由的方式。其原理是当设备转发IP报文时,检查数据报文的源IP地址是否合法,检查的原理是根据数据包的源IP地址查路由表
+
+**本机防攻击**
+
+ 在网络中,存在着大量针对CPU的恶意攻击报文以及需要正常上送CPU的各类报文。针对CPU的恶意攻击报文会导致CPU长时间繁忙的处理攻击报文,从而引发其他业务的断续甚至系统的中断;大量正常的报文也会导致CPU占用率过高,性能下降,从而影响正常的业务
+
+ 为了保护CPU,保证CPU对正常业务的处理和响应,设备提供了本机防攻击功能。本机防攻击针对的是上送CPU的报文,主要用于保护设备自身安全,保证已有业务在发生攻击时的正常运转,避免设备遭受攻击时各业务的相互影响
+
+本机防攻击包括CPU防攻击和攻击溯源两部分:
+
+ CPU防攻击针对上送CPU的报文进行限制和约束,使单位时间内上送CPU报文的数量限制在一定的范围之内,从而保护CPU的安全,保证CPU对业务的正常处理
+
+ 攻击溯源针对DoS(Denial of Service,拒绝服务)攻击进行防御。设备通过对上送CPU的报文进行分析统计,然后对统计的报文设置一定的阈值,将超过阈值的报文判定为攻击报文,再对这些攻击报文根据报文信息找出攻击源用户或者攻击源接口,最后通过日志、告警等方式提醒管理员以便管理员采用一定的措施来保护设备,或者直接丢弃攻击报文以对攻击源进行惩罚
+
+**CPU防攻击**
+
+多级安全机制,保证设备的安全,实现了对设备的分级保护。设备通过以下策略实现对设备的分级保护:
+
+ 第一级:通过黑名单来过滤上送CPU的非法报文
+
+ 第二级:CPCAR,对上送CPU的报文按照协议类型进行速率限制,保证每种协议上送CPU的报文不会过多
+
+ 第三级:对上送CPU的报文,按照协议优先级进行调度,保证优先级高的协议先得到处理
+
+ 第四级:对上送CPU的报文统一限速,对超过统一限速值的报文随机丢弃,保证整体上送CPU的报文不会过多,保护CPU安全
+
+ 动态链路保护功能的CPU报文限速,是指当设备检测到SSH Session数据、Telnet Session数据、HTTP Session数据、FTP Session数据以及BGP Session数据建立时,会启动对此Session的动态链路保护功能,后续上送报文如匹配此Session特征信息,此类数据将会享受高速率上送的权利,由此保证了此Session相关业务的运行可靠性、稳定性
+
+**攻击溯源原理 **
+
+ 攻击溯源包括报文解析、流量分析、攻击源识别和发送日志告警通知管理员以及实施惩罚四个过程
+
+
+
+ 通过图中所示的四个过程,找出攻击源,然后管理员通过ACL或配置黑名单的方式限制攻击源,以保护设备CPU
+
+二:网络设备安全加固部署示例
+
+1.SSH基本配置
+
+
+
+
+
+2.SSH配置示例
+
+ 用户希望安全的远程登录设备,因此配置STelnet方式进行远程的安全登录
+
+ 在R3上配置两个登录用户client001和client002,R1使用client001通过password认证方式登录R3,R2使用client002通过RSA认证方式登录R3。配置安全策略,保证只有R1和R2才能登录设备
+
+
+
+**配置步骤:**
+
+ 在R3生成本地密钥对,实现在服务器端和客户端进行安全的数据交互
+
+ 在R3配置SSH用户client001和**client002**
+
+ 在R3开启STelnet服务功能
+
+ 在R3配置SSH用户client001和client002的服务方式为STelnet
+
+ 在R3配置SSH服务器的端口号,有效防止攻击者对SSH服务标准端口的访问,确保安全性
+
+ 用户client001和client002分别以STelnet方式实现登录R3
+
+**配置:**
+
+```shell
+[R3] rsa local-key-pair create
+The key name will be: Host
+RSA keys defined for Host already exist. Confirm to replace them? (y/n):y
+The range of public key size is (512 ~ 2048).
+NOTES: If the key modulus is less than 2048,
+ It will introduce potential security risks.
+Input the bits in the modulus[default = 2048]:2048
+Generating keys... ......................................................................................+++ ....+++ .......................................++++++++ ..............++++++++
+```
+
+```shell
+[R3] user-interface vty 0 4
+[R3-ui-vty0-4] authentication-mode aaa
+[R3-ui-vty0-4] protocol inbound ssh
+[R3-ui-vty0-4] quit
+[R3] aaa
+[R3-aaa] local-user client001 password irreversible-cipher Huawei@123
+[R3-aaa] local-user client001 privilege level 3
+[R3-aaa] local-user client002 password irreversible-cipher Huawei@123
+[R3-aaa] local-user client002 privilege level 3
+[R3-aaa] quit
+[R3] ssh user client001 authentication-type password
+[R3] ssh user client002 authentication-type rsa
+```
+
+```shell
+[R3] aaa
+[R3-aaa] local-user client001 service-type ssh
+[R3-aaa] local-user client002 service-type ssh
+[R3-aaa] quit
+```
+
+```shell
+[R3] ssh server port 1025
+```
+
+```shell
+# 在R2生成客户端的本地密钥对。
+[R2] rsa local-key-pair create
+The key name will be: Host
+RSA keys defined for Host already exist.
+Confirm to replace them? (y/n):y
+The range of public key size is (512 ~ 2048).
+NOTES: If the key modulus is less than 2048,
+ It will introduce potential security risks.
+Input the bits in the modulus[default = 2048]:2048
+Generating keys... ......................................................................................
++++ ....+++ .......................................++++++++ ..............++++++++
+```
+
+```shell
+# 查看R2生成的RSA密钥对的公钥部分。
+[R2] display rsa local-key-pair public
+Key code: 30820109 02820100 CB0E88EC A1C2CFEA F97126F9 36919C08 0455127B A3A48594 69517096 35626F55 E4FAF0EB FDA2B9E9 5E417B2B E09F38B0 D26FCA73 FE2E3FC4 DFBEC8CF 4ED0C909 E8D975E6 FFC73C81 D13FE71E 759DC805 B0F0E877 4FC9288E BE1E197C 2A7186B0 B56F5573 3A5EA588 29C63E3B 20D56233 8E63278D F941734F 6B359C69 BBAE5A52 EB842179 04B4204D 5DB31D72 97F0C085 DA771F66 0AAADC28 D264CEB9 5BADA92C CDE9F116 D6D99C48 CEBA3A1D 868B053A 32941D85 CCAA9796 A4B55760 0A8108ED DB45DA12 F61634C9 59431600 341FEDEF 5379D565 A8D1953D DEA018A2 72F99FFC 63DE04BF 2A6219BD DF13D705 27D63DEF 83D556BC 5B44D983 8D5EA126 C1EB71CB 0203 010001
+ =====================================================
+Time of Key pair created: 2012-08-06 17:17:44+00:00 Key name: Server Key type: RSA encryption Key =====================================================
+Key code: 3067 0260 DF8AFF3C 28213B94 2292852E E98657EE 11DE5AF4 8A176878 CDD4BD31 55E05735 3080F367 A83A9034 47D534CA 81250C1D 35401DC3 464E9E5F A50202CF A7AD09CD AC3F531C A763F0A0 4C8E51B9 18755400 76AF4A78 225C92C3 01FE0DFF 06908363 0203 010001
+```
+
+```shell
+# 将R2上产生的RSA公钥配置到服务器端(上页display命令显示信息中黑体部分即为客户端产生的RSA公钥,将其拷贝粘贴至服务器端)。
+[R3] rsa peer-public-key rsakey001
+[R3-rsa-public-key] public-key-code begin
+[R3-rsa-key-code] 30820109
+[R3-rsa-key-code] 02820100
+[R3-rsa-key-code] CB0E88EC A1C2CFEA F97126F9 36919C08 0455127B
+[R3-rsa-key-code] ......
+[R3-rsa-key-code] 010001
+[R3-rsa-key-code] public-key-code end
+[R3-rsa-public-key] peer-public-key end
+```
+
+```shell
+# 在R3上为SSH用户client002绑定STelnet客户端的RSA公钥。
+[R3] ssh user client002 assign rsa-key rsakey001
+```
+
+**SSH配置验证**
+
+```shell
+[R1] ssh client first-time enable
+[R1] stelnet 192.168.1.1 1025
+Please input the username:client001
+Trying 192.168.1.1 ...
+Press CTRL+K to abort
+Connected to 192.168.1.1 ...
+The server is not authenticated. Continue to access it?(y/n)[n]:y
+Save the server's public key?(y/n)[n]:y
+The server's public key will be saved with the name 192.168.1.1. Please wait... Enter password:
+ # 显示登录成功
+```
+
+```shell
+[R2] ssh client first-time enable
+[R2] stelnet 192.168.1.1 1025
+Please input the username:client002
+Trying 192.168.1.1 ... Press CTRL+K to abort Connected to 192.168.1.1 ...
+The server is not authenticated. Continue to access it?(y/n)[n]:y
+Save the server's public key?(y/n)[n]:y
+The server's public key will be saved with the name 192.168.1.1. Please wait...
+ # 显示登录成功
+```
+
+3.本机防攻击基本配置
+
+
+
+
+
+4.本机防攻击配置示例
+
+
+
+ 如图所示,位于不同局域网的用户通过R1访问Internet。为分析R1受攻击情况,需要配置攻击溯源检查功能记录攻击源信息
+
+管理员发现存在以下现象:
+
+ 通过攻击溯源检查功能分析可知,Net1中的某个用户经常会发生攻击行为
+
+ R1收到大量的ARP Request报文,影响CPU的正常工作
+
+ R1无法提供FTP服务
+
+ 局域网用户通过DHCP方式动态获取IP地址,但R1未优先处理上送CPU的DHCP报文
+
+ R1收到大量的Telnet报文
+
+管理员希望通过在R1进行配置,以便解决上述问题
+
+**配置过程:**
+
+ 配置黑名单,将Net1网段中的攻击者(0001-c0a8-0102)列入黑名单,阻止其接入网络
+
+ 配置ARP Request报文上送CPU的速率限制,使ARP Request报文限制在较小速率范围内,减少对CPU处理业务的影响
+
+ 配置FTP协议的动态链路保护功能,保证R1正常提供FTP功能
+
+ 配置协议优先级,对DHCP Client报文设置较高的优先级,保证R1优先处理上送CPU的DHCP Client报文
+
+ 关闭R1的Telnet服务器功能,使R1丢弃收到的Telnet报文
+
+```shell
+# 配置黑名单使用的ACL。
+[R1] acl number 4001
+[R1-acl-L2-4001] rule 5 permit source-mac 0001-c0a8-0102
+[R1-acl-L2-4001] quit
+```
+
+```shell
+# 创建防攻击策略。
+[R1] cpu-defend policy devicesafety
+```
+
+```shell
+# 配置攻击溯源检查功能。
+[R1-cpu-defend-policy-devicesafety] auto-defend enable
+[R1-cpu-defend-policy-devicesafety] auto-defend threshold 50
+```
+
+```shell
+# 配置黑名单。
+[R1-cpu-defend-policy-devicesafety] blacklist 1 acl 4001
+```
+
+```shell
+# 配置黑名单。
+[R1-cpu-defend-policy-devicesafety] blacklist 1 acl 4001
+```
+
+```shell
+# 配置FTP协议动态链路保护功能的速率限制值。
+[R1-cpu-defend-policy-devicesafety] application-apperceive packet-type ftp rate-limit 2000
+# 使能FTP协议动态链路保护功能。
+[R1] cpu-defend application-apperceive ftp enable
+```
+
+```shell
+# 应用防攻击策略。
+[R1-cpu-defend-policy-devicesafety] packet-type dhcp-client priority 3
+[R1] cpu-defend-policy devicesafety
+```
+
+```shell
+# 关闭telnet server功能。
+[R1] undo telnet server enable
+```
+
+**本机防攻击配置验证**
+
+```shell
+# 查看上送到主控板的报文的统计信息,丢弃的报文表明设备对arp-request进行了速率限制。
+ display cpu-defend statistics
+Packet Type Pass Packets Drop Packets
+
+8021X 0 0
+arp-miss 5 0
+arp-reply 8090 0
+arp-request 1446576 127773
+bfd 0 0
+bgp 0 0
+bgp4plus 0 0
+dhcp-client 879 0
+dhcp-server 0 0
+```
+
+```shell
+# 查看配置的防攻击策略的信息。
+[R1] display cpu-defend policy devicesafety
+Related slot : <0>
+……
+Slot<0> : Success
+Configuration :
+Blacklist 1 ACL number : 4001
+Packet-type arp-request rate-limit : 64(pps)
+Packet-type dhcp-client priority : 3
+Rate-limit all-packets : 2000(pps)(default)
+Application-apperceive packet-type ftp : 2000(pps)
+Application-apperceive packet-type tftp : 2000(pps)
+```
diff --git a/MD/第四章:动态路由技术(一).md b/MD/第四章:动态路由技术(一).md
new file mode 100644
index 0000000..3d297d9
--- /dev/null
+++ b/MD/第四章:动态路由技术(一).md
@@ -0,0 +1,1522 @@
+第四章:动态路由技术
+
+> 作者:行癫
+
+------
+
+第一节:动态路由概述
+
+一:动态路由概述
+
+ +
+ 静态路由的缺点是不能自动适应网络拓扑的变化,需要人工干预
+
+ 动态路由协议有自己的路由算法,能够自动适应网络拓扑的变化,适用于具有一定数量三层设备的网络
+
+
+
+ 静态路由的缺点是不能自动适应网络拓扑的变化,需要人工干预
+
+ 动态路由协议有自己的路由算法,能够自动适应网络拓扑的变化,适用于具有一定数量三层设备的网络
+
+1.动态路由类型
+
+ +
+**根据路由信息传递的内容、计算路由的算法,可以将动态路由协议分为两大类:**
+
+ 距离矢量协议
+
+ RIP
+
+ 链路状态协议
+
+ OSPF、IS-IS
+
+ BGP使用一种基于距离矢量算法修改后的算法,该算法被称为路径矢量(Path Vector)算法。因此在某些场合下,BGP也被称为路径矢量路由协议
+
+**根据工作范围不同,又可以分为:**
+
+ 内部网关协议IGP(Interior Gateway Protocol):在一个自治系统内部运行。RIP、OSPF、ISIS为常见的IGP协议
+
+ 外部网关协议EGP(Exterior Gateway Protocol):运行于不同自治系统之间。BGP是目前最常用的EGP协议
+
+
+
+**根据路由信息传递的内容、计算路由的算法,可以将动态路由协议分为两大类:**
+
+ 距离矢量协议
+
+ RIP
+
+ 链路状态协议
+
+ OSPF、IS-IS
+
+ BGP使用一种基于距离矢量算法修改后的算法,该算法被称为路径矢量(Path Vector)算法。因此在某些场合下,BGP也被称为路径矢量路由协议
+
+**根据工作范围不同,又可以分为:**
+
+ 内部网关协议IGP(Interior Gateway Protocol):在一个自治系统内部运行。RIP、OSPF、ISIS为常见的IGP协议
+
+ 外部网关协议EGP(Exterior Gateway Protocol):运行于不同自治系统之间。BGP是目前最常用的EGP协议
+
+二:路由高级特性
+
+1.路由递归
+
+ 路由必须有直连的下一跳才能够指导转发,但是路由生成时下一跳可能不是直连的,因此需要计算出一个直连的下一跳和对应的出接口,这个过程叫做路由递归;路由递归也称路由迭代
+
+ +
+
+
+
+
+
+
+2.等价路由
+
+ 路由表中存在等价路由之后,前往该目的网段的IP报文路由器会通过所有有效的接口、下一跳转发,这种转发行为被称为负载分担
+ +
+
+
+3.浮动路由
+
+ +
+ 静态路由支持配置时手动指定优先级,可以通过配置目的地址/掩码相同、优先级不同、下一跳不同的静态路由,实现转发路径的备份
+
+ 浮动路由是主用路由的备份,保证链路故障时提供备份路由,主用路由下一跳可达时该备份路由不会出现的路由表
+
+
+
+ 静态路由支持配置时手动指定优先级,可以通过配置目的地址/掩码相同、优先级不同、下一跳不同的静态路由,实现转发路径的备份
+
+ 浮动路由是主用路由的备份,保证链路故障时提供备份路由,主用路由下一跳可达时该备份路由不会出现的路由表
+
+ +
+ RTA-RTB之间的链路正常时,20.0.0.0/30的两条路由条目都是有效的条目,此时比较优先级,下一跳为10.1.1.2的优先级60,下一跳为10.1.2.2的优先级70,因此下一跳为10.1.1.2的加入路由表
+
+ RTA-RTB之间的链路故障时,10.1.1.2不可达,因此下一跳为10.1.1.2的路由失效,此时前往20.0.0.0/30的路由就只存在一条,该条路由将会被选入路由表。前往20.0.0.1的流量将会被转发到10.1.2.2
+
+
+
+ RTA-RTB之间的链路正常时,20.0.0.0/30的两条路由条目都是有效的条目,此时比较优先级,下一跳为10.1.1.2的优先级60,下一跳为10.1.2.2的优先级70,因此下一跳为10.1.1.2的加入路由表
+
+ RTA-RTB之间的链路故障时,10.1.1.2不可达,因此下一跳为10.1.1.2的路由失效,此时前往20.0.0.0/30的路由就只存在一条,该条路由将会被选入路由表。前往20.0.0.1的流量将会被转发到10.1.2.2
+
+4.路由汇总
+
+ CIDR(无类别域间路由)采用IP地址加掩码长度来标识网络和子网,而不是按照传统的A、B、C等类型对网络地址进行划分
+
+ CIDR容许任意长度的掩码长度,将IP地址看成连续的地址空间,可以使用任意长度的前缀分配,多个连续的前缀可以聚合成一个网络,该特性可以有效的减少路由表条目数量
+
+ +
+**路由汇总需求**
+
+ 子网划分、VLSM解决了地址空间浪费的问题,但同时也带来了新的问题,路由表中的路由条目数量增加
+
+ 为减少路由条目数量可以使用路由汇总
+
+
+
+**路由汇总需求**
+
+ 子网划分、VLSM解决了地址空间浪费的问题,但同时也带来了新的问题,路由表中的路由条目数量增加
+
+ 为减少路由条目数量可以使用路由汇总
+
+ +
+ 对于一个大规模的网络来说,路由器或其他具备路由功能的设备势必需要维护大量的路由表项,为了维护臃肿的路由表,这些设备就不得不耗费大量的资源。同时,由于路由表的规模变大,会导致路由器在查表转发时效率降低。因此在保证网络中的路由器到各网段都具备IP可达性的同时,需要减小设备的路由表规模。一个网络如果具备科学的IP编址,并且进行合理的规划,是可以利用多种手段减小设备路由表规模的。一个非常常见而又有效的办法就是使用路由汇总(Route Summarization)。路由汇总又被称为路由聚合(Route Aggregation),是将一组有规律的路由汇聚成一条路由,从而达到减小路由表规模以及优化设备资源利用率的目的,我们把汇聚之前的这组路由称为精细路由或明细路由,把汇聚之后的这条路由称为汇总路由或聚合路由
+
+**路由汇总简介**
+
+
+
+ 对于一个大规模的网络来说,路由器或其他具备路由功能的设备势必需要维护大量的路由表项,为了维护臃肿的路由表,这些设备就不得不耗费大量的资源。同时,由于路由表的规模变大,会导致路由器在查表转发时效率降低。因此在保证网络中的路由器到各网段都具备IP可达性的同时,需要减小设备的路由表规模。一个网络如果具备科学的IP编址,并且进行合理的规划,是可以利用多种手段减小设备路由表规模的。一个非常常见而又有效的办法就是使用路由汇总(Route Summarization)。路由汇总又被称为路由聚合(Route Aggregation),是将一组有规律的路由汇聚成一条路由,从而达到减小路由表规模以及优化设备资源利用率的目的,我们把汇聚之前的这组路由称为精细路由或明细路由,把汇聚之后的这条路由称为汇总路由或聚合路由
+
+**路由汇总简介**
+
+ +
+ RTA上为了能够前往远端地址,需要为每一个远端网段配置一条明细路由。去往10.1.1.0/24、10.1.2.0/24、10.1.3.0/24…拥有相同下一跳。将拥有相同下一跳,一组有规律的路由汇总成一条路由,这叫做路由汇总,路由汇总可以有效减少路由表项大小
+
+**汇总计算**
+
+
+
+ RTA上为了能够前往远端地址,需要为每一个远端网段配置一条明细路由。去往10.1.1.0/24、10.1.2.0/24、10.1.3.0/24…拥有相同下一跳。将拥有相同下一跳,一组有规律的路由汇总成一条路由,这叫做路由汇总,路由汇总可以有效减少路由表项大小
+
+**汇总计算**
+
+ +
+ 基于一系列连续的、有规律的IP网段,如果需计算相应的汇总路由,且确保得出的汇总路由刚好“囊括”上述IP网段,则需确保汇总路由的掩码长度尽可能长
+
+
+
+ 基于一系列连续的、有规律的IP网段,如果需计算相应的汇总路由,且确保得出的汇总路由刚好“囊括”上述IP网段,则需确保汇总路由的掩码长度尽可能长
+
+5.汇总引发的环路问题
+
+ +
+**解决方案**
+
+
+
+**解决方案**
+
+ +
+ 一般来说一条路由,无论是静态的或者是动态的,都需要关联到一个出接口,路由的出接口指的是设备要到达一个目的网络时的出站接口。路由的出接口可以是该设备的物理接口,例如百兆、千兆以太网接口,也可以是逻辑接口,例如VLAN接口(VLAN Interface),或者隧道(Tunnel)接口等。在众多类型的出接口中,有一种接口非常特殊,那就是Null(无效)接口,这种类型的接口只有一个编号,也就是0。Null0是一个系统保留的逻辑接口,当网络设备在转发某些数据包时,如果使用出接口为Null0的路由,那么这些报文将被直接丢弃,就像被扔进了一个黑洞里,因此出接口为Null0的路由又被称为黑洞路由
+
+
+
+ 一般来说一条路由,无论是静态的或者是动态的,都需要关联到一个出接口,路由的出接口指的是设备要到达一个目的网络时的出站接口。路由的出接口可以是该设备的物理接口,例如百兆、千兆以太网接口,也可以是逻辑接口,例如VLAN接口(VLAN Interface),或者隧道(Tunnel)接口等。在众多类型的出接口中,有一种接口非常特殊,那就是Null(无效)接口,这种类型的接口只有一个编号,也就是0。Null0是一个系统保留的逻辑接口,当网络设备在转发某些数据包时,如果使用出接口为Null0的路由,那么这些报文将被直接丢弃,就像被扔进了一个黑洞里,因此出接口为Null0的路由又被称为黑洞路由
+
+6.精确汇总
+
+
+
+
+
+第二节:动态路由协议RIP
+
+一:RIP 路由信息协议
+
+ 它基于距离矢量算法的协议,使用跳数作为度量来衡量达到目的网络的距离
+
+ 矢量:从源到目的,源只知道目的是谁
+
+ 工作原理:设备之间互相发送request(路由更新请求)消息,收到request消息的设备将路由放到response(路由更新)中发送出去,当网络稳定后,RIP周期性发送response消息,周期为30s一次
+
+1.RIP的报文格式
+
+```shell
+Command:指令/命令(1:request或2:response)
+Version:版本 rip v1 和 rip v2
+Address family identitier 地址族标识 固定取值ipv4
+Ip address : ip地址 在request消息中不显示
+Metric:固定取值16
+```
+
+ RIP v1 以广播的形式发送response路由更新 255.255.255.255
+
+ RIP v2 以组播的形式发送response路由更新 224.0.0.9
+
+ RIP度量(Metric):度量等同于开销
+
+ RIP使用跳数作为度量值来衡量到达目的的网络
+
+ 缺省的情况下,直连网络的路由条数为0,当路由器发送路由更新时,会把度量值加1,不能超过15跳
+
+2.RIPv1和RIPv2的比较
+
+ V1:有类别路由协议,不支持VLSM和CIDR(无类别域间路由)
+
+ 以广播的形式发送报文255.255.255.255
+
+ V2:无类别路由协议,支持VLSM,支持路由聚合与CIDR
+
+ 支持以广播或者组播(224.0.0.9)方式发送报文
+
+ 支持明文认证和MD5密文认证
+
+3.V2的报文格式
+
+ Route Tag:路由标记 用来做路由策略使用
+
+ Subnet Mask:子网掩码
+
+ Next Hop: 下一跳
+
+二:RIP基本配置
+
+ +
+**R1:**
+
+```shell
+system view
+Enter system view, return user view with Ctrl+Z.
+[Huawei]
+[Huawei]int g0/0/0 //进入接口
+[Huawei-GigabitEthernet0/0/0]ip address 10.1.1.1 24 //配置IP地址
+[Huawei-GigabitEthernet0/0/0]int g0/0/1
+[Huawei-GigabitEthernet0/0/1]ip address 10.1.2.1 24
+[Huawei-GigabitEthernet0/0/1]display ip interface brief //查看接口配置
+*down: administratively down
+^down: standby
+(l): loopback
+(s): spoofing
+The number of interface that is UP in Physical is 3
+The number of interface that is DOWN in Physical is 1
+The number of interface that is UP in Protocol is 3
+The number of interface that is DOWN in Protocol is 1
+
+Interface IP Address/Mask Physical Protocol
+GigabitEthernet0/0/0 10.1.1.1/24 up up
+GigabitEthernet0/0/1 10.1.2.1/24 up up
+GigabitEthernet0/0/2 unassigned down down
+NULL0 unassigned up up(s)
+```
+
+**R2:**
+
+```shell
+system-view
+Enter system view, return user view with Ctrl+Z.
+[Huawei]int g0/0/0
+[Huawei-GigabitEthernet0/0/0]ip address 10.1.2.2 24
+[Huawei-GigabitEthernet0/0/0]int g0/0/1
+[Huawei-GigabitEthernet0/0/1]ip address 10.1.3.1 24
+[Huawei-GigabitEthernet0/0/1]display ip interface brief
+*down: administratively down
+^down: standby
+(l): loopback
+(s): spoofing
+The number of interface that is UP in Physical is 3
+The number of interface that is DOWN in Physical is 1
+The number of interface that is UP in Protocol is 3
+The number of interface that is DOWN in Protocol is 1
+
+Interface IP Address/Mask Physical Protocol
+GigabitEthernet0/0/0 10.1.2.2/24 up up
+GigabitEthernet0/0/1 10.1.3.1/24 up up
+GigabitEthernet0/0/2 unassigned down down
+NULL0 unassigned up up(s)
+```
+
+**R3:**
+
+```shell
+sys
+Enter system view, return user view with Ctrl+Z.
+[Huawei]int g0/0/0
+[Huawei-GigabitEthernet0/0/0]ip add 10.1.3.2 24
+[Huawei-GigabitEthernet0/0/0]int g0/0/1
+[Huawei-GigabitEthernet0/0/1]ip add 10.1.4.1 24
+[Huawei-GigabitEthernet0/0/1]display ip interface brief
+*down: administratively down
+^down: standby
+(l): loopback
+(s): spoofing
+The number of interface that is UP in Physical is 3
+The number of interface that is DOWN in Physical is 1
+The number of interface that is UP in Protocol is 3
+The number of interface that is DOWN in Protocol is 1
+
+Interface IP Address/Mask Physical Protocol
+GigabitEthernet0/0/0 10.1.3.2/24 up up
+GigabitEthernet0/0/1 10.1.4.1/24 up up
+GigabitEthernet0/0/2 unassigned down down
+NULL0 unassigned up up(s)
+```
+
+
+
+**R1:**
+
+```shell
+system view
+Enter system view, return user view with Ctrl+Z.
+[Huawei]
+[Huawei]int g0/0/0 //进入接口
+[Huawei-GigabitEthernet0/0/0]ip address 10.1.1.1 24 //配置IP地址
+[Huawei-GigabitEthernet0/0/0]int g0/0/1
+[Huawei-GigabitEthernet0/0/1]ip address 10.1.2.1 24
+[Huawei-GigabitEthernet0/0/1]display ip interface brief //查看接口配置
+*down: administratively down
+^down: standby
+(l): loopback
+(s): spoofing
+The number of interface that is UP in Physical is 3
+The number of interface that is DOWN in Physical is 1
+The number of interface that is UP in Protocol is 3
+The number of interface that is DOWN in Protocol is 1
+
+Interface IP Address/Mask Physical Protocol
+GigabitEthernet0/0/0 10.1.1.1/24 up up
+GigabitEthernet0/0/1 10.1.2.1/24 up up
+GigabitEthernet0/0/2 unassigned down down
+NULL0 unassigned up up(s)
+```
+
+**R2:**
+
+```shell
+system-view
+Enter system view, return user view with Ctrl+Z.
+[Huawei]int g0/0/0
+[Huawei-GigabitEthernet0/0/0]ip address 10.1.2.2 24
+[Huawei-GigabitEthernet0/0/0]int g0/0/1
+[Huawei-GigabitEthernet0/0/1]ip address 10.1.3.1 24
+[Huawei-GigabitEthernet0/0/1]display ip interface brief
+*down: administratively down
+^down: standby
+(l): loopback
+(s): spoofing
+The number of interface that is UP in Physical is 3
+The number of interface that is DOWN in Physical is 1
+The number of interface that is UP in Protocol is 3
+The number of interface that is DOWN in Protocol is 1
+
+Interface IP Address/Mask Physical Protocol
+GigabitEthernet0/0/0 10.1.2.2/24 up up
+GigabitEthernet0/0/1 10.1.3.1/24 up up
+GigabitEthernet0/0/2 unassigned down down
+NULL0 unassigned up up(s)
+```
+
+**R3:**
+
+```shell
+sys
+Enter system view, return user view with Ctrl+Z.
+[Huawei]int g0/0/0
+[Huawei-GigabitEthernet0/0/0]ip add 10.1.3.2 24
+[Huawei-GigabitEthernet0/0/0]int g0/0/1
+[Huawei-GigabitEthernet0/0/1]ip add 10.1.4.1 24
+[Huawei-GigabitEthernet0/0/1]display ip interface brief
+*down: administratively down
+^down: standby
+(l): loopback
+(s): spoofing
+The number of interface that is UP in Physical is 3
+The number of interface that is DOWN in Physical is 1
+The number of interface that is UP in Protocol is 3
+The number of interface that is DOWN in Protocol is 1
+
+Interface IP Address/Mask Physical Protocol
+GigabitEthernet0/0/0 10.1.3.2/24 up up
+GigabitEthernet0/0/1 10.1.4.1/24 up up
+GigabitEthernet0/0/2 unassigned down down
+NULL0 unassigned up up(s)
+```
+
+1.结果
+
+ +
+
+
+2.抓包
+
+ +
+
+
+第三节:开放式最短路径优先OSPF
+
+一:动态路由协议分类
+
+1.距离矢量路由协议
+
+ 运行距离矢量路由协议的路由器周期性的泛洪自己的路由表,通过路由的交互,每台路由器都从相邻的路由器学习到路由,并加载到自己的路由表中
+
+ 对于网络中的所有路由器而言,路由器并不清楚网络的拓扑,只是简单的知道要去往某个目的方向在哪里,距离有多远,这即是距离矢量算法的本质
+
+ +
+
+
+2.链路状态路由协议—LSA泛洪
+
+ 与巨鹿矢量路由协议不同,链路状态路由协议通告的是链路状态而不是路由表,运行链路状态路由协议的路由器之间是首先会建立一个协议的邻居关系,然后彼此之间开始交互LSA(Link State Advertisement 链路状态通告)
+
+ +
+ 链路状态通告,可以简单的理解为每台路由器都产生一个描述自己直连接口状态(包括接口的开销、与邻居路由器之间的关系等)的通告
+
+
+
+ 链路状态通告,可以简单的理解为每台路由器都产生一个描述自己直连接口状态(包括接口的开销、与邻居路由器之间的关系等)的通告
+
+3.链路状态路由协议-LSDB组建
+
+ 每台路由器都会产生LSAs,路由器将接收到的LSAs放入到自己的LSDB(链路状态数据库),路由器通过LSDB,掌握了全网的拓扑
+
+ +
+
+
+4.链路状态路由协议—SPF计算
+
+ 每台路由器基于LSDB,使用SPF(Shortest Path First 最短路径优先)算法进行计算,每台路由器都计算出一颗以自己为根的、无环的、拥有最短路径的“树”,有了这颗树,路由器就已经知道了到达网络各个角落的优选路径
+
+ +
+ SPF是OSPF路由协议的一个核心算法,用来在一个复杂的网络中做出路由优选的决策
+
+
+
+ SPF是OSPF路由协议的一个核心算法,用来在一个复杂的网络中做出路由优选的决策
+
+5.链路状态路由协议—路由表生成
+
+ 路由器将计算出来的优选路径,加载进自己的路由表
+
+ +
+
+
+6.链路状态路由协议总结
+
+ +
+**链路状态路由协议有四个步骤:**
+
+ 第一步是建立相邻路由器之间的邻居关系
+
+ 第二步是邻居之间交互链路状态信息和同步LSDB
+
+ 第三步是进行优选路径计算
+
+ 第四步是根据最短路径树生成路由表项加载到路由表
+
+
+
+**链路状态路由协议有四个步骤:**
+
+ 第一步是建立相邻路由器之间的邻居关系
+
+ 第二步是邻居之间交互链路状态信息和同步LSDB
+
+ 第三步是进行优选路径计算
+
+ 第四步是根据最短路径树生成路由表项加载到路由表
+
+二:OSPF协议
+
+1.OSPF简介
+
+ OSPF是IETF定义的一种基于链路状态的内部网关路由协议。目前针对IPv4协议使用的是OSPF Version 2(RFC2328);针对IPv6协议使用OSPF Version 3(RFC2740)
+
+**OSPF有以下优点:**
+
+ 基于SPF算法,以“累计链路开销”作为选路参考值
+
+ 采用组播形式收发部分协议报文
+
+ 支持区域划分
+
+ 支持对等价路由进行负载分担
+
+ 支持报文认证
+
+**OSPF应用场景**
+
+ +
+ 大型企业网络中通常部署OSPF实现各个楼宇的网络之间的路由可达
+
+ 核心和汇聚层部署在OSPF骨干区域
+
+ 接入和汇聚层部署在OSPF非骨干区域
+
+注意:
+
+ 接入层:接入层利用光纤、双绞线、同轴电缆、无线接入技术等传输介质,实现与用户连接,并进行业务和带宽的分配。接入层目的是允许终端用户连接到网络,因此接入层交换机具有低成本和高端口密度特性
+
+ 汇聚层:汇聚层为接入层提供基于策略的连接,如地址合并,协议过滤,路由服务,认证管理等。通过网段划分实现与网络隔离,可以防止网络故障蔓延和影响到核心层。汇聚层同时也可以提供接入层虚拟网之间的互连,控制和限制接入层对核心层的访问,保证核心层的安全和稳定
+
+ 核心层:核心层的功能主要是实现骨干网络之间的优化传输,核心层任务的重点通常是冗余能力、可靠性和高速的传输
+
+
+
+ 大型企业网络中通常部署OSPF实现各个楼宇的网络之间的路由可达
+
+ 核心和汇聚层部署在OSPF骨干区域
+
+ 接入和汇聚层部署在OSPF非骨干区域
+
+注意:
+
+ 接入层:接入层利用光纤、双绞线、同轴电缆、无线接入技术等传输介质,实现与用户连接,并进行业务和带宽的分配。接入层目的是允许终端用户连接到网络,因此接入层交换机具有低成本和高端口密度特性
+
+ 汇聚层:汇聚层为接入层提供基于策略的连接,如地址合并,协议过滤,路由服务,认证管理等。通过网段划分实现与网络隔离,可以防止网络故障蔓延和影响到核心层。汇聚层同时也可以提供接入层虚拟网之间的互连,控制和限制接入层对核心层的访问,保证核心层的安全和稳定
+
+ 核心层:核心层的功能主要是实现骨干网络之间的优化传输,核心层任务的重点通常是冗余能力、可靠性和高速的传输
+
+2.OSPF基础术语
+
+**Router ID**
+
+ Router ID用于在自治系统中唯一标识一台运行OSPF的路由器,它是一个32位的无符号整数
+
+Router ID选举规则如下:
+
+ 手动配置OSPF路由器的Router ID(建议手动配置)
+
+ 如果没有手动配置Router ID,则路由器使用Loopback接口中最大的IP地址作为Router ID
+
+ 如果没有配置Loopback接口,则路由器使用物理接口中最大的IP地址作为Router ID
+
+ +
+ Router ID一旦选定,之后如果要更改的话就需要重启OSPF进程
+
+ 在实际工程中,推荐手工指定OSPF路由设备的Router ID。首先规划出一个私有网段用于OSPF的Router ID选择,例如:192.168.1.0/24。在启用OSPF进程前在每个OSPF路由器上建立一个Loopback接口,使用一个32位掩码的私有地址作为其IP地址,这个32位的私有地址即作为该路由设备的Router ID。如果没有特殊要求,这个Loopback接口地址可以不发布在OSPF网络中
+
+**区域**
+
+ OSPF Area用于标识一个OSPF的区域
+
+ 区域是从逻辑上将设备划分为不同的组,每个组用区域号(Area ID)来标识
+
+ OSPF的区域ID是一个32bit的非负整数,按点分十进制的形式(与IPv4地址的格式一样)呈现,例如Area0.0.0.1。为了简便起见,我们也会采用十进制的形式来表示
+
+
+
+ Router ID一旦选定,之后如果要更改的话就需要重启OSPF进程
+
+ 在实际工程中,推荐手工指定OSPF路由设备的Router ID。首先规划出一个私有网段用于OSPF的Router ID选择,例如:192.168.1.0/24。在启用OSPF进程前在每个OSPF路由器上建立一个Loopback接口,使用一个32位掩码的私有地址作为其IP地址,这个32位的私有地址即作为该路由设备的Router ID。如果没有特殊要求,这个Loopback接口地址可以不发布在OSPF网络中
+
+**区域**
+
+ OSPF Area用于标识一个OSPF的区域
+
+ 区域是从逻辑上将设备划分为不同的组,每个组用区域号(Area ID)来标识
+
+ OSPF的区域ID是一个32bit的非负整数,按点分十进制的形式(与IPv4地址的格式一样)呈现,例如Area0.0.0.1。为了简便起见,我们也会采用十进制的形式来表示
+
+ +
+**度量值**
+
+ OSPF使用Cost(开销)作为路由的度量值。每一个激活了OSPF的接口都会维护一个接口Cost值,缺省的接口Cost = 100 Mbit/s ➗接口带宽。其中100 Mbit/s为OSPF指定的缺省参考值,该值是可配置的
+
+ OSPF以“累计cost”为开销值,也就是流量从源网络到目的网络所经过所有路由器的出接口的cost总和
+
+
+
+**度量值**
+
+ OSPF使用Cost(开销)作为路由的度量值。每一个激活了OSPF的接口都会维护一个接口Cost值,缺省的接口Cost = 100 Mbit/s ➗接口带宽。其中100 Mbit/s为OSPF指定的缺省参考值,该值是可配置的
+
+ OSPF以“累计cost”为开销值,也就是流量从源网络到目的网络所经过所有路由器的出接口的cost总和
+
+ +
+注意:
+
+ 在实际应用中,推荐根据接口带宽大小手动配置Cost值,而不是修改OSPF参考带宽
+
+
+
+注意:
+
+ 在实际应用中,推荐根据接口带宽大小手动配置Cost值,而不是修改OSPF参考带宽
+
+3.OSPF三大表项
+
+**邻居表**
+
+OSPF有三张重要的表项,OSPF邻居表、LSDB和OSPF路由表。对于OSPF的邻居表,需要了解:
+
+ OSPF在传递链路状态信息之前,需先建立OSPF邻居关系
+
+ OSPF的邻居关系通过交互Hello报文建立
+
+ OSPF邻居表显示了OSPF路由器之间的邻居状态,使用display ospf peer查看
+
+ +
+**LSDB**
+
+ LSDB会保存自己产生的及从邻居收到的LSA信息,本例中R1的LSDB包含了三条LSA
+
+ Type标识LSA的类型,AdvRouter标识发送LSA的路由器
+
+ 使用命令行display ospf lsdb查看LSDB表
+
+
+
+**LSDB**
+
+ LSDB会保存自己产生的及从邻居收到的LSA信息,本例中R1的LSDB包含了三条LSA
+
+ Type标识LSA的类型,AdvRouter标识发送LSA的路由器
+
+ 使用命令行display ospf lsdb查看LSDB表
+
+ +
+**OSPF路由表**
+
+ OSPF路由表和路由器路由表是两张不同的表。本例中OSPF路由表有三条路由
+
+ OSPF路由表包含Destination、Cost和NextHop等指导转发的信息
+
+ 使用命令display ospf routing查看OSPF路由表
+
+
+
+**OSPF路由表**
+
+ OSPF路由表和路由器路由表是两张不同的表。本例中OSPF路由表有三条路由
+
+ OSPF路由表包含Destination、Cost和NextHop等指导转发的信息
+
+ 使用命令display ospf routing查看OSPF路由表
+
+ +
+注意:
+
+ 路由器路由表通常称为全局路由表,并非所有OSPF路由都可以放到路由器路由表
+
+
+
+注意:
+
+ 路由器路由表通常称为全局路由表,并非所有OSPF路由都可以放到路由器路由表
+
+3.OSPF报文格式和类型
+
+ OSPF一共定义了5种类型的报文,不同类型的OSPF报文有相同的头部格式
+
+ OSPF报文直接采用IP封装,在报文的IP头部中,协议号为89
+
+ +
+ Version :对于当前所使用的OSPFv2,该字段的值为2
+
+ Router ID:表示生成此报文的路由器的Router ID
+
+ Area ID:表示此报文需要被通告到的区域
+
+ Type:类型字段
+
+ Packet length:表示整个OSPF报文的长度,单位是字节
+
+ Checksum:校验字段,其校验的范围是整个OSPF报文,包括OSPF报文头部
+
+ Auth Type:为0时表示不认证;为1时表示简单的明文密码认证;为2时表示加密(MD5)认证
+
+ Authentication:认证所需的信息。该字段的内容随AuType的值不同而不同
+
+
+
+ Version :对于当前所使用的OSPFv2,该字段的值为2
+
+ Router ID:表示生成此报文的路由器的Router ID
+
+ Area ID:表示此报文需要被通告到的区域
+
+ Type:类型字段
+
+ Packet length:表示整个OSPF报文的长度,单位是字节
+
+ Checksum:校验字段,其校验的范围是整个OSPF报文,包括OSPF报文头部
+
+ Auth Type:为0时表示不认证;为1时表示简单的明文密码认证;为2时表示加密(MD5)认证
+
+ Authentication:认证所需的信息。该字段的内容随AuType的值不同而不同
+
+4.OSPF工作过程
+
+ +
+**建立邻居关系**
+
+ OSPF使用Hello报文发现和建立邻居关系
+
+ 在以太网链路上,缺省时,OSPF采用组播的形式发送Hello报文(目的地址224.0.0.5)
+
+ OSPF Hello报文中包含了路由器的Router ID、邻居列表等信息
+
+
+
+**建立邻居关系**
+
+ OSPF使用Hello报文发现和建立邻居关系
+
+ 在以太网链路上,缺省时,OSPF采用组播的形式发送Hello报文(目的地址224.0.0.5)
+
+ OSPF Hello报文中包含了路由器的Router ID、邻居列表等信息
+
+ +
+注意:
+
+ R1和R2路由器相互发送Hello报文,第一个Hello报文包含的邻居列表为空
+
+ R2收到R1发送的Hello报文后,如果各项参数匹配,再次发送Hello报文时,将R1加入自己的邻居列表
+
+ 在以太网链路上,通常以组播形式发送Hello报文
+
+ 224.0.0.5的组播地址为OSPF设备的预留IP组播地址
+
+ 224.0.0.6的组播地址为OSPF DR/BDR的预留IP组播地址
+
+ 对于不支持组播的链路,OSPF支持采用单播的方式发送Hello报文
+
+**Hello报文**
+
+Hello报文的主要作用:
+
+ 邻居发现:自动发现邻居路由器
+
+ 邻居建立:完成Hello报文中的参数协商,建立邻居关系
+
+ 邻居保持:通过周期性发送和接收,检测邻居运行状态
+
+
+
+注意:
+
+ R1和R2路由器相互发送Hello报文,第一个Hello报文包含的邻居列表为空
+
+ R2收到R1发送的Hello报文后,如果各项参数匹配,再次发送Hello报文时,将R1加入自己的邻居列表
+
+ 在以太网链路上,通常以组播形式发送Hello报文
+
+ 224.0.0.5的组播地址为OSPF设备的预留IP组播地址
+
+ 224.0.0.6的组播地址为OSPF DR/BDR的预留IP组播地址
+
+ 对于不支持组播的链路,OSPF支持采用单播的方式发送Hello报文
+
+**Hello报文**
+
+Hello报文的主要作用:
+
+ 邻居发现:自动发现邻居路由器
+
+ 邻居建立:完成Hello报文中的参数协商,建立邻居关系
+
+ 邻居保持:通过周期性发送和接收,检测邻居运行状态
+
+ +
+ Network Mask:发送Hello报文的接口的网络掩码
+
+ HelloInterval:发送Hello报文的时间间隔。通常为10s
+
+ RouterDeadInterval:失效时间。如果在此时间内未收到邻居发来的Hello报文,则认为邻居失效。通常为40s
+
+ Neighbor:邻居,以Router ID标识
+
+ Options:
+
+ E:是否支持外部路由
+
+ MC:是否支持转发组播数据包
+
+ N/P:是否为NSSA区域
+
+ Router Priority:DR优先级。默认为1。如果设置为0,则路由器不能参与DR或BDR的选举
+
+ Designated Router:DR的接口地址
+
+ Backup Designated Router:BDR的接口地址
+
+**邻接关系建立**
+
+
+
+ Network Mask:发送Hello报文的接口的网络掩码
+
+ HelloInterval:发送Hello报文的时间间隔。通常为10s
+
+ RouterDeadInterval:失效时间。如果在此时间内未收到邻居发来的Hello报文,则认为邻居失效。通常为40s
+
+ Neighbor:邻居,以Router ID标识
+
+ Options:
+
+ E:是否支持外部路由
+
+ MC:是否支持转发组播数据包
+
+ N/P:是否为NSSA区域
+
+ Router Priority:DR优先级。默认为1。如果设置为0,则路由器不能参与DR或BDR的选举
+
+ Designated Router:DR的接口地址
+
+ Backup Designated Router:BDR的接口地址
+
+**邻接关系建立**
+
+ +
+DD报文部分字段解释:
+
+ I:当发送连续多个DD报文时,如果这是第一个DD报文,则置为1,否则置为0
+
+ M (More):当发送连续多个DD报文时,如果是最后一个DD报文,则置为0。否则置为1,表示后面还有其他的DD报文
+
+ MS (Master/Slave):当两台OSPF路由器交换DD报文时,首先需要确定双方的主从关系,Router ID大的一方会成为Master。当值为1时表示发送方为Master
+
+ DD sequence number:DD报文序列号。主从双方利用序列号来保证DD报文传输的可靠性和完整性
+
+注意:
+
+ R1和R2的Router ID分别为10.0.1.1和10.0.2.2并且二者已建立了邻居关系。当R1的邻居状态变为ExStart后,R1会发送第一个DD报文。此报文中,M-bit设置为1,表示后续还有DD报文要发送,MS-bit设置为1,表示R1宣告自己为Master。DD序列号被随机设置为X,I-bit设置为1,表示这是第一个DD报文
+
+ 同样当R2的邻居状态变为ExStart后,R2也会发送第一个DD报文。此报文中,DD序列号被随机设置为Y(I-bit=1,M-bit=1,MS-bit=1,含义同上)。由于R2的Router ID较大,所以R2将成为真正的Master。收到此报文后,R1会产生一个Negotiation-Done事件,并将邻居状态从ExStart变为Exchange
+
+ 当R1的邻居状态变为Exchange后,R1会发送一个新的DD报文,此报文中包含了LSDB的摘要信息,序列号设置为R2在步骤2中使用的序列号Y,I-bit=0,表示这不是第一个DD报文,M-bit=0,表示这是最后一个包含LSDB摘要信息的DD报文,MS-bit=0,表示R1宣告自己为Slave。收到此报文后,R2将邻居状态从ExStart变为Exchange
+
+ 当R2的邻居状态变为Exchange后,R2会发送一个新的DD报文,此报文包含了LSDB的摘要信息。DD序列号设置为Y+1, MS-bit=1,表示R2宣告自己为Master
+
+ 虽然R1不需要发送新的包含LSDB摘要信息的DD报文,但是作为Slave,R1需要对Master发送的每一个DD报文进行确认。所以,R1向R2发送一个新的DD报文,序列号为Y+1,该报文内容为空。发送完此报文后,RTA产生一个Exchange-Done事件,将邻居状态变为Loading。R2收到此报文后,会将邻居状态变为Full(假设R2的LSDB是最新最全的,不需要向R1请求更新)
+
+**DD报文**
+
+ DD报文包含LSA头部信息,包括LS Type、LS ID、Advertising Router、LS Sequence Number、LS Checksum
+
+
+
+DD报文部分字段解释:
+
+ I:当发送连续多个DD报文时,如果这是第一个DD报文,则置为1,否则置为0
+
+ M (More):当发送连续多个DD报文时,如果是最后一个DD报文,则置为0。否则置为1,表示后面还有其他的DD报文
+
+ MS (Master/Slave):当两台OSPF路由器交换DD报文时,首先需要确定双方的主从关系,Router ID大的一方会成为Master。当值为1时表示发送方为Master
+
+ DD sequence number:DD报文序列号。主从双方利用序列号来保证DD报文传输的可靠性和完整性
+
+注意:
+
+ R1和R2的Router ID分别为10.0.1.1和10.0.2.2并且二者已建立了邻居关系。当R1的邻居状态变为ExStart后,R1会发送第一个DD报文。此报文中,M-bit设置为1,表示后续还有DD报文要发送,MS-bit设置为1,表示R1宣告自己为Master。DD序列号被随机设置为X,I-bit设置为1,表示这是第一个DD报文
+
+ 同样当R2的邻居状态变为ExStart后,R2也会发送第一个DD报文。此报文中,DD序列号被随机设置为Y(I-bit=1,M-bit=1,MS-bit=1,含义同上)。由于R2的Router ID较大,所以R2将成为真正的Master。收到此报文后,R1会产生一个Negotiation-Done事件,并将邻居状态从ExStart变为Exchange
+
+ 当R1的邻居状态变为Exchange后,R1会发送一个新的DD报文,此报文中包含了LSDB的摘要信息,序列号设置为R2在步骤2中使用的序列号Y,I-bit=0,表示这不是第一个DD报文,M-bit=0,表示这是最后一个包含LSDB摘要信息的DD报文,MS-bit=0,表示R1宣告自己为Slave。收到此报文后,R2将邻居状态从ExStart变为Exchange
+
+ 当R2的邻居状态变为Exchange后,R2会发送一个新的DD报文,此报文包含了LSDB的摘要信息。DD序列号设置为Y+1, MS-bit=1,表示R2宣告自己为Master
+
+ 虽然R1不需要发送新的包含LSDB摘要信息的DD报文,但是作为Slave,R1需要对Master发送的每一个DD报文进行确认。所以,R1向R2发送一个新的DD报文,序列号为Y+1,该报文内容为空。发送完此报文后,RTA产生一个Exchange-Done事件,将邻居状态变为Loading。R2收到此报文后,会将邻居状态变为Full(假设R2的LSDB是最新最全的,不需要向R1请求更新)
+
+**DD报文**
+
+ DD报文包含LSA头部信息,包括LS Type、LS ID、Advertising Router、LS Sequence Number、LS Checksum
+
+ +
+ Interface MTU:指示在不分片的情况下,此接口最大可发出的IP报文长度。在两个邻居发送DD报文中包含MTU参数,如果收到的DD报文中MTU和本端的MTU不相等,则丢弃该DD报文。缺省情况下,华为设备未开启MTU检查
+
+ Optinons:字段同Hello报文
+
+
+
+ Interface MTU:指示在不分片的情况下,此接口最大可发出的IP报文长度。在两个邻居发送DD报文中包含MTU参数,如果收到的DD报文中MTU和本端的MTU不相等,则丢弃该DD报文。缺省情况下,华为设备未开启MTU检查
+
+ Optinons:字段同Hello报文
+
+ +
+ R1开始向R2发送LSR报文,请求那些在Exchange状态下通过DD报文发现的、并且在本地LSDB中没有的链路状态信息
+
+ R2向R1发送LSU报文,LSU报文中包含了那些被请求的链路状态的详细信息。R1在完成LSU报文的接收之后,且没有其他待请求的LSA后,会将邻居状态从Loading变为Full
+
+ R1向R2发送LSAck报文,作为对LSU报文的确认
+
+**DR与BDR的作用**
+
+MA网络中的问题:
+
+ n×(n−1)/2个邻接关系,管理复杂
+
+ 重复的LSA泛洪,造成资源浪费
+
+
+
+ R1开始向R2发送LSR报文,请求那些在Exchange状态下通过DD报文发现的、并且在本地LSDB中没有的链路状态信息
+
+ R2向R1发送LSU报文,LSU报文中包含了那些被请求的链路状态的详细信息。R1在完成LSU报文的接收之后,且没有其他待请求的LSA后,会将邻居状态从Loading变为Full
+
+ R1向R2发送LSAck报文,作为对LSU报文的确认
+
+**DR与BDR的作用**
+
+MA网络中的问题:
+
+ n×(n−1)/2个邻接关系,管理复杂
+
+ 重复的LSA泛洪,造成资源浪费
+
+ +
+解决方案:
+
+在MA网络中选举DR:
+
+ DR(Designated Router,指定路由器)负责在MA网络建立和维护邻接关系并负责LSA的同步
+
+ DR与其他所有路由器形成邻接关系并交换链路状态信息,其他路由器之间不直接交换链路状态信息
+
+ 为了规避单点故障风险,通过选举BDR(备份指定路由器) ,在DR失效时快速接管DR的工作
+
+
+
+解决方案:
+
+在MA网络中选举DR:
+
+ DR(Designated Router,指定路由器)负责在MA网络建立和维护邻接关系并负责LSA的同步
+
+ DR与其他所有路由器形成邻接关系并交换链路状态信息,其他路由器之间不直接交换链路状态信息
+
+ 为了规避单点故障风险,通过选举BDR(备份指定路由器) ,在DR失效时快速接管DR的工作
+
+ +
+ MA( Multiple Access,多路访问 )分为BMA( Broadcast Multi-Access,广播多路访问)和NBMA(Non-Broadcast Multiple Access,非广播多路访问)。以太网链路组成的网络是典型的BMA网络。帧中继链路通过逻辑上的划分组成典型的NBMA网络
+
+ DRother:既不是DR也不是BDR的路由器就是DRother路由器
+
+**DR与BDR的选举规则**
+
+ DR/BDR的选举是非抢占式的
+
+ DR/BDR的选举是基于接口的
+
+ 接口的DR优先级越大越优先
+
+ 接口的DR优先级相等时,Router ID越大越优先
+
+
+
+ MA( Multiple Access,多路访问 )分为BMA( Broadcast Multi-Access,广播多路访问)和NBMA(Non-Broadcast Multiple Access,非广播多路访问)。以太网链路组成的网络是典型的BMA网络。帧中继链路通过逻辑上的划分组成典型的NBMA网络
+
+ DRother:既不是DR也不是BDR的路由器就是DRother路由器
+
+**DR与BDR的选举规则**
+
+ DR/BDR的选举是非抢占式的
+
+ DR/BDR的选举是基于接口的
+
+ 接口的DR优先级越大越优先
+
+ 接口的DR优先级相等时,Router ID越大越优先
+
+ +
+**广播链路或者NBMA链路上DR和BDR的选举过程如下:**
+
+ 接口UP后,发送Hello报文,同时进入到Waiting状态。在Waiting状态下会有一个WaitingTimer,该计时器的长度与DeadTimer是一样的。默认值为40秒,用户不可自行调整
+
+ 在WaitingTimer触发前,发送的Hello报文是没有DR和BDR字段的。在Waiting阶段,如果收到Hello报文中有DR和BDR,那么直接承认网络中的DR和BDR,而不会触发选举。直接离开Waiting状态,开始邻居同步
+
+ 假设网络中已经存在一个DR和一个BDR,这时新加入网络中的路由器,不论它的Router ID或者DR优先级有多大,都会承认现网中已有的DR和BDR
+
+ 当DR因为故障Down掉之后,BDR会继承DR的位置,剩下的优先级大于0的路由器会竞争成为新的BDR
+
+ 只有当不同Router ID,或者配置不同DR优先级的路由器同时起来,在同一时刻进行DR选举才会应用DR选举规则产生DR
+
+**不同网络类型中DR与BDR的选举操作**
+
+ P2MP:point-to-multipoint,点到多点
+
+
+
+**广播链路或者NBMA链路上DR和BDR的选举过程如下:**
+
+ 接口UP后,发送Hello报文,同时进入到Waiting状态。在Waiting状态下会有一个WaitingTimer,该计时器的长度与DeadTimer是一样的。默认值为40秒,用户不可自行调整
+
+ 在WaitingTimer触发前,发送的Hello报文是没有DR和BDR字段的。在Waiting阶段,如果收到Hello报文中有DR和BDR,那么直接承认网络中的DR和BDR,而不会触发选举。直接离开Waiting状态,开始邻居同步
+
+ 假设网络中已经存在一个DR和一个BDR,这时新加入网络中的路由器,不论它的Router ID或者DR优先级有多大,都会承认现网中已有的DR和BDR
+
+ 当DR因为故障Down掉之后,BDR会继承DR的位置,剩下的优先级大于0的路由器会竞争成为新的BDR
+
+ 只有当不同Router ID,或者配置不同DR优先级的路由器同时起来,在同一时刻进行DR选举才会应用DR选举规则产生DR
+
+**不同网络类型中DR与BDR的选举操作**
+
+ P2MP:point-to-multipoint,点到多点
+
+ +
+**OSPF状态机**
+
+
+
+**OSPF状态机**
+
+ +
+
+
+5.OSPF基本配置
+
+
+
+
+
+6.OSPF配置举例
+
+ +
+```shell
+以R2为例:
+[R2]ospf 1 router-id 10.0.2.2
+[R2-ospf-1]area 0.0.0.0
+[R2-ospf-1-area-0.0.0.0] network 10.0.12.0 0.0.0.255
+[R2-ospf-1-area-0.0.0.0] network 10.0.24.2 0.0.0.0
+[R2-ospf-1-area-0.0.0.0] network 10.0.35.2 0.0.0.0
+```
+
+注意:
+
+**ospf发布network 192.168.1.1 0.0.0.0 和network 192.168.1.0 0.0.0.255区别**
+
+开放不同
+
+ network 192.168.1.1 0.0.0.0:network 192.168.1.1 0.0.0.0指定向外部IP地址开放了192.168.1.1这个ip地址的路由。
+
+ network 192.168.1.0 0.0.0.255:network 192.168.1.0 0.0.0.255向外部IP地址开放了192.168.1.0这个ip地址里24位网段里的所有子地址的路由。
+
+通信不同
+
+ network 192.168.1.1 0.0.0.0:其他ip地址的路由只能通过network 192.168.1.1 0.0.0.0和同一192.168.1这个ip地址进行通信。
+
+ network 192.168.1.0 0.0.0.255:其他ip地址的路由可以通过network 192.168.1.0 0.0.0.255能和同一192.168.1以下网段里的所有子地址之间进行通信。
+
+**OSPF配置验证**
+
+display ospf interface all可查看当前设备所有激活OSPF的接口信息:
+
+ 时间参数,例如Hello报文发送间隔,死亡时间。
+
+ 接口的链路类型、接口的MTU。
+
+ 对于以太网链路,可查看DR的接口地址,DR的优先级。
+
+```shell
+[R2]display ospf interface all
+ OSPF Process 1 with Router ID 10.0.2.2
+ Area: 0.0.0.0
+ Interface: 10.0.12.2 (GigabitEthernet0/0/0)
+ Cost: 1 State: DR Type: Broadcast MTU: 1500 Priority: 1
+ Designated Router: 10.0.12.2
+ Backup Designated Router: 10.0.12.1
+ Timers: HELLO 10 , Dead 40 , Poll 120 , Retransmit 5 , Transmit Delay 1
+
+ Interface: 10.0.235.2 (GigabitEthernet0/0/1)
+ Cost: 1 State: DROther Type: Broadcast MTU: 1500 Priority: 1
+ Designated Router: 10.0.235.5
+ Backup Designated Router: 10.0.235.3
+ Timers: HELLO 10 , Dead 40 , Poll 120 , Retransmit 5 , Transmit Delay 1
+
+ Interface: 10.0.24.2 (Serial1/0/1) --> 10.0.24.4
+ Cost: 48 State: P-2-P Type: P2P MTU: 1500
+ Timers: HELLO 10 , Dead 40 , Poll 120 , Retransmit 5 , Transmit Delay 1
+```
+
+display ospf peer可查看当前设备的邻居状态:
+
+ 邻居路由器的Router ID
+
+ 邻居状态,例如FULL,TWO-WAY,DOWN等
+
+
+
+```shell
+以R2为例:
+[R2]ospf 1 router-id 10.0.2.2
+[R2-ospf-1]area 0.0.0.0
+[R2-ospf-1-area-0.0.0.0] network 10.0.12.0 0.0.0.255
+[R2-ospf-1-area-0.0.0.0] network 10.0.24.2 0.0.0.0
+[R2-ospf-1-area-0.0.0.0] network 10.0.35.2 0.0.0.0
+```
+
+注意:
+
+**ospf发布network 192.168.1.1 0.0.0.0 和network 192.168.1.0 0.0.0.255区别**
+
+开放不同
+
+ network 192.168.1.1 0.0.0.0:network 192.168.1.1 0.0.0.0指定向外部IP地址开放了192.168.1.1这个ip地址的路由。
+
+ network 192.168.1.0 0.0.0.255:network 192.168.1.0 0.0.0.255向外部IP地址开放了192.168.1.0这个ip地址里24位网段里的所有子地址的路由。
+
+通信不同
+
+ network 192.168.1.1 0.0.0.0:其他ip地址的路由只能通过network 192.168.1.1 0.0.0.0和同一192.168.1这个ip地址进行通信。
+
+ network 192.168.1.0 0.0.0.255:其他ip地址的路由可以通过network 192.168.1.0 0.0.0.255能和同一192.168.1以下网段里的所有子地址之间进行通信。
+
+**OSPF配置验证**
+
+display ospf interface all可查看当前设备所有激活OSPF的接口信息:
+
+ 时间参数,例如Hello报文发送间隔,死亡时间。
+
+ 接口的链路类型、接口的MTU。
+
+ 对于以太网链路,可查看DR的接口地址,DR的优先级。
+
+```shell
+[R2]display ospf interface all
+ OSPF Process 1 with Router ID 10.0.2.2
+ Area: 0.0.0.0
+ Interface: 10.0.12.2 (GigabitEthernet0/0/0)
+ Cost: 1 State: DR Type: Broadcast MTU: 1500 Priority: 1
+ Designated Router: 10.0.12.2
+ Backup Designated Router: 10.0.12.1
+ Timers: HELLO 10 , Dead 40 , Poll 120 , Retransmit 5 , Transmit Delay 1
+
+ Interface: 10.0.235.2 (GigabitEthernet0/0/1)
+ Cost: 1 State: DROther Type: Broadcast MTU: 1500 Priority: 1
+ Designated Router: 10.0.235.5
+ Backup Designated Router: 10.0.235.3
+ Timers: HELLO 10 , Dead 40 , Poll 120 , Retransmit 5 , Transmit Delay 1
+
+ Interface: 10.0.24.2 (Serial1/0/1) --> 10.0.24.4
+ Cost: 48 State: P-2-P Type: P2P MTU: 1500
+ Timers: HELLO 10 , Dead 40 , Poll 120 , Retransmit 5 , Transmit Delay 1
+```
+
+display ospf peer可查看当前设备的邻居状态:
+
+ 邻居路由器的Router ID
+
+ 邻居状态,例如FULL,TWO-WAY,DOWN等
+
+ +
+```shell
+display ospf peer
+ OSPF Process 1 with Router ID 10.0.2.2
+ Area 0.0.0.0 interface 10.0.12.2(GigabitEthernet0/0/0)'s neighbors
+ Router ID: 10.0.1.1 Address: 10.0.12.1
+ State: Full Mode:Nbr is Slave Priority: 1
+ DR: 10.0.12.2 BDR: 10.0.12.1 MTU: 0
+ Dead timer due in 28 sec
+ Retrans timer interval: 5
+ Neighbor is up for 00:01:31
+ Authentication Sequence: [ 0 ]
+
+ Area 0.0.0.0 interface 10.0.235.2(GigabitEthernet0/0/1)'s neighbors
+ Router ID: 10.0.3.3 Address: 10.0.235.3
+ State: Full Mode:Nbr is Master Priority: 1
+ DR: 10.0.235.5 BDR: 10.0.235.3 MTU: 0
+ Dead timer due in 30 sec
+ Retrans timer interval: 5
+ Neighbor is up for 00:01:31
+ Authentication Sequence: [ 0 ]
+```
+
+ 在P2P网络中不需要选举DR/BDR。因此在本例中,查看R2的OSPF邻居表时,会发现其Serial1/0/1接口的数据结构中DR/BDR字段为None
+
+
+
+```shell
+display ospf peer
+ OSPF Process 1 with Router ID 10.0.2.2
+ Area 0.0.0.0 interface 10.0.12.2(GigabitEthernet0/0/0)'s neighbors
+ Router ID: 10.0.1.1 Address: 10.0.12.1
+ State: Full Mode:Nbr is Slave Priority: 1
+ DR: 10.0.12.2 BDR: 10.0.12.1 MTU: 0
+ Dead timer due in 28 sec
+ Retrans timer interval: 5
+ Neighbor is up for 00:01:31
+ Authentication Sequence: [ 0 ]
+
+ Area 0.0.0.0 interface 10.0.235.2(GigabitEthernet0/0/1)'s neighbors
+ Router ID: 10.0.3.3 Address: 10.0.235.3
+ State: Full Mode:Nbr is Master Priority: 1
+ DR: 10.0.235.5 BDR: 10.0.235.3 MTU: 0
+ Dead timer due in 30 sec
+ Retrans timer interval: 5
+ Neighbor is up for 00:01:31
+ Authentication Sequence: [ 0 ]
+```
+
+ 在P2P网络中不需要选举DR/BDR。因此在本例中,查看R2的OSPF邻居表时,会发现其Serial1/0/1接口的数据结构中DR/BDR字段为None
+
+ +
+```shell
+ display ospf peer
+ OSPF Process 1 with Router ID 10.0.2.2
+Area 0.0.0.0 interface 10.0.235.2(GigabitEthernet0/0/1)'s neighbors
+Router ID: 10.0.5.5 Address: 10.0.235.5
+ State: Full Mode:Nbr is Master Priority: 1
+ DR: 10.0.235.5 BDR: 10.0.235.3 MTU: 0
+ Dead timer due in 40 sec
+ Retrans timer interval: 0
+ Neighbor is up for 00:01:27
+ Authentication Sequence: [ 0 ]
+
+ Area 0.0.0.0 interface 10.0.24.2(Serial1/0/1)'s neighbors
+ Router ID: 10.0.4.4 Address: 10.0.24.4
+ State: Full Mode:Nbr is Master Priority: 1
+ DR: None BDR: None MTU: 0
+ Dead timer due in 35 sec
+ Retrans timer interval: 5
+ Neighbor is up for 00:01:56
+ Authentication Sequence: [ 0 ]
+```
+
+display ospf lsdb可查看当前设备的LSDB:
+
+ LSDB由多种类型的LSA构成,所有的LSA都有相同的报文头部格式,其中关键字段如Type、LinkState ID、AdvRouter等。下节课程将重点介绍LSA的详细信息
+
+```shell
+display ospf lsdb
+
+ OSPF Process 1 with Router ID 10.0.2.2
+ Link State Database
+
+ Area: 0.0.0.0
+Type LinkState ID AdvRouter Age Len Sequence Metric
+Router 10.0.4.4 10.0.4.4 662 72 80000006 48
+Router 10.0.2.2 10.0.2.2 625 72 8000000C 1
+Router 10.0.1.1 10.0.1.1 638 60 80000007 1
+Router 10.0.5.5 10.0.5.5 634 60 8000000B 1
+Router 10.0.3.3 10.0.3.3 639 60 80000009 1
+Network 10.0.235.5 10.0.5.5 634 36 80000005 0
+Network 10.0.12.2 10.0.2.2 629 32 80000003 0
+```
+
+display ospf routing可查看当前设备的OSPF路由表:
+
+ 从R2的OSPF路由表可看出,它已经通过OSPF获知到达全网的路由
+
+```shell
+display ospf routing
+
+ OSPF Process 1 with Router ID 10.0.2.2
+ Routing Tables
+Destination Cost Type NextHop AdvRouter Area
+10.0.12.0/24 1 Transit 10.0.12.2 10.0.2.2 0.0.0.0
+10.0.24.0/24 48 Stub 10.0.24.2 10.0.2.2 0.0.0.0
+10.0.235.0/24 1 Transit 10.0.235.2 10.0.2.2 0.0.0.0
+10.0.13.0/24 49 Stub 10.0.12.1 10.0.1.1 0.0.0.0
+10.0.13.0/24 49 Stub 10.0.235.3 10.0.3.3 0.0.0.0
+10.0.45.0/24 49 Stub 10.0.235.5 10.0.5.5 0.0.0.0
+```
+
+
+
+```shell
+ display ospf peer
+ OSPF Process 1 with Router ID 10.0.2.2
+Area 0.0.0.0 interface 10.0.235.2(GigabitEthernet0/0/1)'s neighbors
+Router ID: 10.0.5.5 Address: 10.0.235.5
+ State: Full Mode:Nbr is Master Priority: 1
+ DR: 10.0.235.5 BDR: 10.0.235.3 MTU: 0
+ Dead timer due in 40 sec
+ Retrans timer interval: 0
+ Neighbor is up for 00:01:27
+ Authentication Sequence: [ 0 ]
+
+ Area 0.0.0.0 interface 10.0.24.2(Serial1/0/1)'s neighbors
+ Router ID: 10.0.4.4 Address: 10.0.24.4
+ State: Full Mode:Nbr is Master Priority: 1
+ DR: None BDR: None MTU: 0
+ Dead timer due in 35 sec
+ Retrans timer interval: 5
+ Neighbor is up for 00:01:56
+ Authentication Sequence: [ 0 ]
+```
+
+display ospf lsdb可查看当前设备的LSDB:
+
+ LSDB由多种类型的LSA构成,所有的LSA都有相同的报文头部格式,其中关键字段如Type、LinkState ID、AdvRouter等。下节课程将重点介绍LSA的详细信息
+
+```shell
+display ospf lsdb
+
+ OSPF Process 1 with Router ID 10.0.2.2
+ Link State Database
+
+ Area: 0.0.0.0
+Type LinkState ID AdvRouter Age Len Sequence Metric
+Router 10.0.4.4 10.0.4.4 662 72 80000006 48
+Router 10.0.2.2 10.0.2.2 625 72 8000000C 1
+Router 10.0.1.1 10.0.1.1 638 60 80000007 1
+Router 10.0.5.5 10.0.5.5 634 60 8000000B 1
+Router 10.0.3.3 10.0.3.3 639 60 80000009 1
+Network 10.0.235.5 10.0.5.5 634 36 80000005 0
+Network 10.0.12.2 10.0.2.2 629 32 80000003 0
+```
+
+display ospf routing可查看当前设备的OSPF路由表:
+
+ 从R2的OSPF路由表可看出,它已经通过OSPF获知到达全网的路由
+
+```shell
+display ospf routing
+
+ OSPF Process 1 with Router ID 10.0.2.2
+ Routing Tables
+Destination Cost Type NextHop AdvRouter Area
+10.0.12.0/24 1 Transit 10.0.12.2 10.0.2.2 0.0.0.0
+10.0.24.0/24 48 Stub 10.0.24.2 10.0.2.2 0.0.0.0
+10.0.235.0/24 1 Transit 10.0.235.2 10.0.2.2 0.0.0.0
+10.0.13.0/24 49 Stub 10.0.12.1 10.0.1.1 0.0.0.0
+10.0.13.0/24 49 Stub 10.0.235.3 10.0.3.3 0.0.0.0
+10.0.45.0/24 49 Stub 10.0.235.5 10.0.5.5 0.0.0.0
+```
+
+第四节:OSPF路由计算
+
+一:区域内路由计算
+
+1.LSA概述
+
+**LSA的基本概念**
+
+ LSA是OSPF进行路由计算的关键依据
+
+ OSPF的LSU报文可以携带多种不同类型的LSA
+
+ 各种类型的LSA拥有相同的报文头部
+
+ 链路状态类型、链路状态ID、通告路由器三元组唯一地标识了一个LSA
+
+ 链路状态老化时间 、链路状态序列号 、校验和用于判断LSA的新旧
+
+ +
+ LS Age(链路状态老化时间):此字段表示LSA已经生存的时间,单位是秒
+
+ Options(可选项):每一个bit都对应了OSPF所支持的某种特性
+
+ LS Type(链路状态类型):指示本LSA的类型
+
+ Link State ID(链路状态ID):不同的LSA,对该字段的定义不同
+
+ Advertising Router(通告路由器):产生该LSA的路由器的Router ID
+
+ LS Sequence Number(链路状态序列号):当LSA每次有新的实例产生时,序列号就会增加
+
+ LS Checksum(校验和):用于保证数据的完整性和准确性
+
+ Length:是一个包含LSA头部在内的LSA的总长度值
+
+注意:
+
+ LS Age:当LSA被始发时,该字段为0,随着LSA在网络中被泛洪,该时间逐渐累加,当到达MaxAge(缺省值为3600s)时,LSA不再用于路由计算
+
+ LS Sequence Number:该字段用于判断LSA的新旧或是否存在重复的实例。序列号范围是0x80000001-0x7FFFFFFF,路由器始发一个LSA,序列号为0x80000001,之后每次更新序列号加1,当LSA达到最大序列号时,重新产生该LSA,并且把序列号设置为0x80000001
+
+
+
+ LS Age(链路状态老化时间):此字段表示LSA已经生存的时间,单位是秒
+
+ Options(可选项):每一个bit都对应了OSPF所支持的某种特性
+
+ LS Type(链路状态类型):指示本LSA的类型
+
+ Link State ID(链路状态ID):不同的LSA,对该字段的定义不同
+
+ Advertising Router(通告路由器):产生该LSA的路由器的Router ID
+
+ LS Sequence Number(链路状态序列号):当LSA每次有新的实例产生时,序列号就会增加
+
+ LS Checksum(校验和):用于保证数据的完整性和准确性
+
+ Length:是一个包含LSA头部在内的LSA的总长度值
+
+注意:
+
+ LS Age:当LSA被始发时,该字段为0,随着LSA在网络中被泛洪,该时间逐渐累加,当到达MaxAge(缺省值为3600s)时,LSA不再用于路由计算
+
+ LS Sequence Number:该字段用于判断LSA的新旧或是否存在重复的实例。序列号范围是0x80000001-0x7FFFFFFF,路由器始发一个LSA,序列号为0x80000001,之后每次更新序列号加1,当LSA达到最大序列号时,重新产生该LSA,并且把序列号设置为0x80000001
+
+2.常见LSA的类型
+
+| **类型** | **名称** | **描述** |
+| -------- | ---------------------------------- | ------------------------------------------------------------ |
+| 1 | 路由器LSA(Router LSA) | 每个设备都会产生,描述了设备的链路状态和开销,该LSA只能在接口所属的区域内泛洪 |
+| 2 | 网络LSA(Network LSA) | 由DR产生,描述该DR所接入的MA网络中所有与之形成邻接关系的路由器,以及DR自己。该LSA只能在接口所属区域内泛洪 |
+| 3 | 网络汇总LSA(Network Summary LSA) | 由ABR产生,描述区域内某个网段的路由,该类LSA主要用于区域间路由的传递 |
+| 4 | ASBR汇总LSA(ASBR Summary LSA) | 由ABR产生,描述到ASBR的路由,通告给除ASBR所在区域的其他相关区域。 |
+| 5 | AS外部LSA(AS External LSA) | 由ASBR产生,用于描述到达OSPF域外的路由 |
+| 7 | 非完全末梢区域LSA(NSSA LSA) | 由ASBR产生,用于描述到达OSPF域外的路由。NSSA LSA与AS外部LSA功能类似,但是泛洪范围不同。NSSA LSA只能在始发的NSSA内泛洪,并且不能直接进入Area0。NSSA的ABR会将7类LSA转换成5类LSA注入到Area0 |
+
+3.Router LSA
+
+ Router LSA(1类LSA):每台OSPF路由器都会产生。它描述了该路由器直连接口的信息
+
+ Router LSA只能在所属的区域内泛洪
+
+ +
+ V (Virtual Link ) :如果产生此LSA的路由器是虚连接的端点,则置为1
+
+ E (External ): 如果产生此LSA的路由器是ASBR,则置为1
+
+ B (Border ):如果产生此LSA的路由器是ABR,则置为1
+
+ links :LSA中的Link(链路)数量。Router LSA使用Link来承载路由器直连接口的信息
+
+**详解**
+
+ Router LSA使用Link来承载路由器直连接口的信息
+
+ 每条Link均包含“链路类型”、“链路ID”、“链路数据”以及“度量值”这几个关键信息
+
+ 路由器可能会采用一个或者多个Link来描述某个接口
+
+
+
+ V (Virtual Link ) :如果产生此LSA的路由器是虚连接的端点,则置为1
+
+ E (External ): 如果产生此LSA的路由器是ASBR,则置为1
+
+ B (Border ):如果产生此LSA的路由器是ABR,则置为1
+
+ links :LSA中的Link(链路)数量。Router LSA使用Link来承载路由器直连接口的信息
+
+**详解**
+
+ Router LSA使用Link来承载路由器直连接口的信息
+
+ 每条Link均包含“链路类型”、“链路ID”、“链路数据”以及“度量值”这几个关键信息
+
+ 路由器可能会采用一个或者多个Link来描述某个接口
+
+ +
+**Router LSA描述P2P网络**
+
+
+
+**Router LSA描述P2P网络**
+
+ +
+```shell
+display ospf lsdb router self-originate
+ Type : Router
+ Ls id : 10.0.1.1
+ Adv rtr : 10.0.1.1
+ * Link ID: 10.0.3.3
+ Data : 10.0.13.1
+ Link Type: P-2-P
+ Metric : 48
+ * Link ID: 10.0.13.0
+ Data : 255.255.255.0
+ Link Type: StubNet
+ Metric : 48
+ Priority : Low
+```
+
+
+
+```shell
+display ospf lsdb router self-originate
+ Type : Router
+ Ls id : 10.0.1.1
+ Adv rtr : 10.0.1.1
+ * Link ID: 10.0.3.3
+ Data : 10.0.13.1
+ Link Type: P-2-P
+ Metric : 48
+ * Link ID: 10.0.13.0
+ Data : 255.255.255.0
+ Link Type: StubNet
+ Metric : 48
+ Priority : Low
+```
+
+ +
+**Router LSA描述TransNet**
+
+
+
+**Router LSA描述TransNet**
+
+ +
+
+
+4.Network LSA
+
+ Network LSA(2类LSA) :由DR产生,描述本网段的链路状态,在所属的区域内传播
+
+ Network LSA 记录了该网段内所有与DR建立了邻接关系的OSPF路由器,同时携带了该网段的网络掩码
+
+ +
+ Link State ID :DR的接口IP地址
+
+ Network Mask:MA网络的子网掩码
+
+ Attached Router:连接到该MA网络的路由器的Router-ID(与该DR建立了邻接关系的邻居的Router-ID,以及DR自己的Router-ID),如果有多台路由器接入该MA网络,则使用多个字段描述
+
+**Network LSA描述MA网络**
+
+
+
+ Link State ID :DR的接口IP地址
+
+ Network Mask:MA网络的子网掩码
+
+ Attached Router:连接到该MA网络的路由器的Router-ID(与该DR建立了邻接关系的邻居的Router-ID,以及DR自己的Router-ID),如果有多台路由器接入该MA网络,则使用多个字段描述
+
+**Network LSA描述MA网络**
+
+ +
+
+
+二:区域间路由计算
+
+1.大型网络中,单区域OSPF存在的问题
+
+ +
+ 一系列连续的OSPF路由器构成的网络称为OSPF域(Domain)
+
+ OSPF要求网络内的路由器同步LSDB,实现对于网络的一致认知
+
+ 当网络规模越来越大时,LSDB将变得非常臃肿,设备基于该LSDB进行路由计算,其负担也极大地增加了,此外路由器的路由表规模也变大了,这些无疑都将加大路由器的性能损耗
+
+ 当网络拓扑发生变更时,这些变更需要被扩散到整个网络,并可能引发整网的路由重计算
+
+ 单区域的设计,使得OSPF无法部署路由汇总
+
+
+
+ 一系列连续的OSPF路由器构成的网络称为OSPF域(Domain)
+
+ OSPF要求网络内的路由器同步LSDB,实现对于网络的一致认知
+
+ 当网络规模越来越大时,LSDB将变得非常臃肿,设备基于该LSDB进行路由计算,其负担也极大地增加了,此外路由器的路由表规模也变大了,这些无疑都将加大路由器的性能损耗
+
+ 当网络拓扑发生变更时,这些变更需要被扩散到整个网络,并可能引发整网的路由重计算
+
+ 单区域的设计,使得OSPF无法部署路由汇总
+
+2.区域划分
+
+ +
+
+
+ +
+ Router LSA和Network LSA只在区域内泛洪,因此通过区域划分在一定程度上降低网络设备的内存及CPU的消耗
+
+**划分区域后,路由器可以分为两种角色:**
+
+ 区域内部路由器(Internal Router):该类设备的所有接口都属于同一个OSPF区域。如R1、R4、R5
+
+ 区域边界路由器(Area Border Router):该类设备接口分别连接两个及两个以上的不同区域。如R2、R3
+
+**区域间路由信息传递**
+
+ OSPF区域间路由信息传递是通过ABR产生的Network Summary LSA(3类LSA)实现的
+
+ 以192.168.1.0/24路由信息为例:
+
+ R2依据Area 1内所泛洪的Router LSA及Network LSA计算得出192.168.1.0/24路由(区域内路由),并将该路由通过Network Summary LSA通告到Area 0。R3根据该LSA可计算出到达192.168.1.0/24的区域间路由
+
+ R3重新生成一份Network Summary LSA通告到Area 2中,至此所有OSPF区域都能学习到去往192.168.1.0/24的路由
+
+
+
+ Router LSA和Network LSA只在区域内泛洪,因此通过区域划分在一定程度上降低网络设备的内存及CPU的消耗
+
+**划分区域后,路由器可以分为两种角色:**
+
+ 区域内部路由器(Internal Router):该类设备的所有接口都属于同一个OSPF区域。如R1、R4、R5
+
+ 区域边界路由器(Area Border Router):该类设备接口分别连接两个及两个以上的不同区域。如R2、R3
+
+**区域间路由信息传递**
+
+ OSPF区域间路由信息传递是通过ABR产生的Network Summary LSA(3类LSA)实现的
+
+ 以192.168.1.0/24路由信息为例:
+
+ R2依据Area 1内所泛洪的Router LSA及Network LSA计算得出192.168.1.0/24路由(区域内路由),并将该路由通过Network Summary LSA通告到Area 0。R3根据该LSA可计算出到达192.168.1.0/24的区域间路由
+
+ R3重新生成一份Network Summary LSA通告到Area 2中,至此所有OSPF区域都能学习到去往192.168.1.0/24的路由
+
+ +
+**Network Summary LSA**
+
+ Network Summary LSA(3类LSA)由ABR产生,用于向一个区域通告到达另一个区域的路由
+
+
+
+**Network Summary LSA**
+
+ Network Summary LSA(3类LSA)由ABR产生,用于向一个区域通告到达另一个区域的路由
+
+ +
+ LS Type:取值3,代表Network Summary LSA
+
+ Link State ID:路由的目的网络地址
+
+ Advertising Router:生成LSA的Router ID
+
+ Network Mask:路由的网络掩码
+
+ metric:到目的地址的路由开销
+
+**Network Summary LSA示例**
+
+
+
+ LS Type:取值3,代表Network Summary LSA
+
+ Link State ID:路由的目的网络地址
+
+ Advertising Router:生成LSA的Router ID
+
+ Network Mask:路由的网络掩码
+
+ metric:到目的地址的路由开销
+
+**Network Summary LSA示例**
+
+ +
+ 此LSA是R2产生的,用于向Area0通告到达192.168.1.0/24的区域间路由
+
+```SHELL
+display ospf lsdb summary 192.168.1.0
+ OSPF Process 1 with Router ID 10.0.2.2
+ Area: 0.0.0.0
+ Link State Database
+
+ Type : Sum-Net
+ Ls id : 192.168.1.0
+ Adv rtr : 10.0.2.2
+ Ls age : 86
+ Len : 28
+ Options : E
+ seq# : 80000001
+ chksum : 0x7c6d
+ Net mask : 255.255.255.0
+ Tos0 metric: 1
+ Priority : Low
+```
+
+**R1和R3的路由计算**
+
+
+
+ 此LSA是R2产生的,用于向Area0通告到达192.168.1.0/24的区域间路由
+
+```SHELL
+display ospf lsdb summary 192.168.1.0
+ OSPF Process 1 with Router ID 10.0.2.2
+ Area: 0.0.0.0
+ Link State Database
+
+ Type : Sum-Net
+ Ls id : 192.168.1.0
+ Adv rtr : 10.0.2.2
+ Ls age : 86
+ Len : 28
+ Options : E
+ seq# : 80000001
+ chksum : 0x7c6d
+ Net mask : 255.255.255.0
+ Tos0 metric: 1
+ Priority : Low
+```
+
+**R1和R3的路由计算**
+
+ +
+ 通过区域内SPF的计算,R1到达R2的Cost值为1,R3到达R2的Cost值为2
+
+ R1和R3根据收到的Network Summary LSA进行路由计算
+
+ R1将到达R2和Cost值和Network Summary LSA所携带的Cost值相加,因此R1到达192.168.1.0/24的Cost值为2
+
+ R3将到达R2和Cost值和Network Summary LSA所携带的Cost值相加,因此R3到达192.168.1.0/24的Cost值为3
+
+**R5的路由计算**
+
+
+
+ 通过区域内SPF的计算,R1到达R2的Cost值为1,R3到达R2的Cost值为2
+
+ R1和R3根据收到的Network Summary LSA进行路由计算
+
+ R1将到达R2和Cost值和Network Summary LSA所携带的Cost值相加,因此R1到达192.168.1.0/24的Cost值为2
+
+ R3将到达R2和Cost值和Network Summary LSA所携带的Cost值相加,因此R3到达192.168.1.0/24的Cost值为3
+
+**R5的路由计算**
+
+ +
+ R3作为ABR,它通过Area 0内泛洪的Network Summary LSA计算出到达192.168.1.0/24的路由,然后重新向Area 2注入到达该网段的Network Summary LSA,其中包含自己到达该网段的Cost(值为3)
+
+ R5在SPF中计算得知到达R3的Cost为1,因此R5到达192.168.1.0/24的Cost为4
+
+**区域间路由计算结果验证**
+
+
+
+ R3作为ABR,它通过Area 0内泛洪的Network Summary LSA计算出到达192.168.1.0/24的路由,然后重新向Area 2注入到达该网段的Network Summary LSA,其中包含自己到达该网段的Cost(值为3)
+
+ R5在SPF中计算得知到达R3的Cost为1,因此R5到达192.168.1.0/24的Cost为4
+
+**区域间路由计算结果验证**
+
+ +
+**区域间路由的防环机制**
+
+
+
+**区域间路由的防环机制**
+
+ +
+ OSPF要求所有的非骨干区域必须与Area0直接相连,区域间路由需经由Area0中转
+
+ 区域间的路由传递不能发生在两个非骨干区域之间,这使得OSPF的区域架构在逻辑上形成了一个类似星型的拓扑
+
+注意:
+
+ OSPF要求ABR设备至少有一个接口属于骨干区域
+
+
+
+ OSPF要求所有的非骨干区域必须与Area0直接相连,区域间路由需经由Area0中转
+
+ 区域间的路由传递不能发生在两个非骨干区域之间,这使得OSPF的区域架构在逻辑上形成了一个类似星型的拓扑
+
+注意:
+
+ OSPF要求ABR设备至少有一个接口属于骨干区域
+
+ +
+ ABR不会将描述到达某个区域内网段路由的3类LSA再注入回该区域
+
+**虚连接的作用及配置**
+
+ OSPF要求骨干区域必须是连续的,但是并不要求物理上连续,可以使用虚连接使骨干区域在逻辑上连续
+
+ 虚连接可以在任意两个ABR上建立,但是要求这两个ABR都有端口连接到一个相同的非骨干区域
+
+
+
+ ABR不会将描述到达某个区域内网段路由的3类LSA再注入回该区域
+
+**虚连接的作用及配置**
+
+ OSPF要求骨干区域必须是连续的,但是并不要求物理上连续,可以使用虚连接使骨干区域在逻辑上连续
+
+ 虚连接可以在任意两个ABR上建立,但是要求这两个ABR都有端口连接到一个相同的非骨干区域
+
+ +
+```shell
+[R2-ospf-1]ospf 1
+[R2-ospf-1]area 1
+[R2-ospf-1-area-0.0.0.1]vlink-peer 10.0.3.3
+
+[R3-ospf-1]ospf 1
+[R3-ospf-1]area 1
+[R3-ospf-1-area-0.0.0.1]vlink-peer 10.0.2.2
+```
+
+
+
+```shell
+[R2-ospf-1]ospf 1
+[R2-ospf-1]area 1
+[R2-ospf-1-area-0.0.0.1]vlink-peer 10.0.3.3
+
+[R3-ospf-1]ospf 1
+[R3-ospf-1]area 1
+[R3-ospf-1-area-0.0.0.1]vlink-peer 10.0.2.2
+```
+
+三:外部路由计算
+
+1.OSPF外部路由引入背景
+
+网络中存在部分链路未开启OSPF协议如:
+
+ 路由器连接外部网络使用静态路由或者BGP协议
+
+ 服务器直连的链路未开启OSPF协议
+
+ +
+
+
+2.外部路由引入的基本概念
+
+ ASBR(AS Boundary Router):自治系统边界路由器。只要一台OSPF设备引入了外部路由,它就成为了ASBR
+
+ ASBR将外部路由信息以AS-external LSA(5类LSA)的形式在OSPF网络内泛洪
+
+ +
+```shell
+在OSPF进程下,通过如下命令引入外部路由。设备支持引入BGP、ISIS、OSPF、直连以及静态路由。
+import-route { limit limit-number | { bgp [ permit-ibgp ] | direct | unr | rip [ process-id-rip ] | static | isis [ process-id-isis ] | ospf [ process-id-ospf ] } [ cost cost | type type | tag tag | route-policy route-policy-name ] * }
+```
+
+**AS-external LSA详解**
+
+ AS-external LSA(5类LSA):由ASBR产生,描述到达AS外部的路由,该LSA会被通告到所有的区域(除了Stub区域和NSSA区域)
+
+
+
+```shell
+在OSPF进程下,通过如下命令引入外部路由。设备支持引入BGP、ISIS、OSPF、直连以及静态路由。
+import-route { limit limit-number | { bgp [ permit-ibgp ] | direct | unr | rip [ process-id-rip ] | static | isis [ process-id-isis ] | ospf [ process-id-ospf ] } [ cost cost | type type | tag tag | route-policy route-policy-name ] * }
+```
+
+**AS-external LSA详解**
+
+ AS-external LSA(5类LSA):由ASBR产生,描述到达AS外部的路由,该LSA会被通告到所有的区域(除了Stub区域和NSSA区域)
+
+ +
+ LS Type:取值5,代表AS-external-LSA
+
+ Link State ID:外部路由的目的网络地址
+
+ Advertising Router:生成该LSA的Router ID
+
+ Network Mask:网络掩码
+
+ E :该外部路由所使用的度量值类型
+
+ 0:度量值类型为Metric-Type-1
+
+ 1:度量值类型为Metric-Type-2
+
+ metric:到目的网络的路由开销
+
+ Forwarding Address(FA):到所通告的目的地址的报文将被转发到这个地址
+
+**AS-external LSA示例**
+
+
+
+ LS Type:取值5,代表AS-external-LSA
+
+ Link State ID:外部路由的目的网络地址
+
+ Advertising Router:生成该LSA的Router ID
+
+ Network Mask:网络掩码
+
+ E :该外部路由所使用的度量值类型
+
+ 0:度量值类型为Metric-Type-1
+
+ 1:度量值类型为Metric-Type-2
+
+ metric:到目的网络的路由开销
+
+ Forwarding Address(FA):到所通告的目的地址的报文将被转发到这个地址
+
+**AS-external LSA示例**
+
+ +
+ R1与服务器直连的网段为192.168.1.0/24,在R1上将直连路由引入OSPF,此时R1会向OSPF注入用于描述192.168.1.0/24路由的AS-external-LSA,该LSA将在整个OSPF域内泛洪
+
+```shell
+display ospf lsdb ase self-originate
+ OSPF Process 1 with Router ID 10.0.1.1
+ Link State Database
+ Type : External
+ Ls id : 192.168.1.0
+ Adv rtr : 10.0.1.1
+ Ls age : 1340
+ Len : 36
+ Options : E
+ seq# : 80000004
+ chksum : 0xb5cc
+ Net mask : 255.255.255.0
+ TOS 0 Metric: 1
+ E type : 2
+ Forwarding Address : 0.0.0.0
+ Tag : 1
+ Priority : Low
+```
+
+**ASBR-Summary LSA**
+
+ ASBR-Summary LSA(4类LSA):由ABR产生,描述到ASBR的路由,通告给除ASBR所在区域的其他相关区
+
+
+
+ R1与服务器直连的网段为192.168.1.0/24,在R1上将直连路由引入OSPF,此时R1会向OSPF注入用于描述192.168.1.0/24路由的AS-external-LSA,该LSA将在整个OSPF域内泛洪
+
+```shell
+display ospf lsdb ase self-originate
+ OSPF Process 1 with Router ID 10.0.1.1
+ Link State Database
+ Type : External
+ Ls id : 192.168.1.0
+ Adv rtr : 10.0.1.1
+ Ls age : 1340
+ Len : 36
+ Options : E
+ seq# : 80000004
+ chksum : 0xb5cc
+ Net mask : 255.255.255.0
+ TOS 0 Metric: 1
+ E type : 2
+ Forwarding Address : 0.0.0.0
+ Tag : 1
+ Priority : Low
+```
+
+**ASBR-Summary LSA**
+
+ ASBR-Summary LSA(4类LSA):由ABR产生,描述到ASBR的路由,通告给除ASBR所在区域的其他相关区
+
+ +
+
+
+ +
+ LS Type:取值4,代表ASBR-Summary LSA
+
+ Link State ID :ASBR的Router ID
+
+ Advertising Router:生成LSA的Router ID
+
+ Network Mask:仅保留,无意义
+
+ metric:到目的地址的路由开销
+
+**ASBR-Summary LSA示例**
+
+
+
+ LS Type:取值4,代表ASBR-Summary LSA
+
+ Link State ID :ASBR的Router ID
+
+ Advertising Router:生成LSA的Router ID
+
+ Network Mask:仅保留,无意义
+
+ metric:到目的地址的路由开销
+
+**ASBR-Summary LSA示例**
+
+ +
+ 以R3向Area 2通告的ASBR-Summary LSA为例
+
+```shell
+display ospf lsdb asbr self-originate
+Area: 0.0.0.2
+ Link State Database
+ Type : Sum-Asbr
+ Ls id : 10.0.1.1 //ASBR的Router ID
+
+ Adv rtr : 10.0.3.3
+ Ls age : 15
+ Len : 28
+ Options : E
+ seq# : 80000005
+ chksum : 0xf456
+ Tos 0 metric: 1 //R3到达ASBR的开销
+```
+
+
+
+ 以R3向Area 2通告的ASBR-Summary LSA为例
+
+```shell
+display ospf lsdb asbr self-originate
+Area: 0.0.0.2
+ Link State Database
+ Type : Sum-Asbr
+ Ls id : 10.0.1.1 //ASBR的Router ID
+
+ Adv rtr : 10.0.3.3
+ Ls age : 15
+ Len : 28
+ Options : E
+ seq# : 80000005
+ chksum : 0xf456
+ Tos 0 metric: 1 //R3到达ASBR的开销
+```
+
+3.区分OSPF外部路由的2种度量值类型
+
+**Metric-Type-1**
+
+ 当外部路由的开销与自治系统内部的路由开销相当,并且和OSPF自身路由的开销具有可比性时,可以认为这类路由的可信程度较高,将其配置成Metric-Type-1
+
+ Metric-Type-1外部路由的开销为AS内部开销(路由器到ASBR的开销)与AS外部开销之和
+
+**Metric-Type-2**
+
+ 当ASBR到AS之外的开销远远大于在AS之内到达ASBR的开销时,可以认为这类路由的可信程度较低,将其配置成Metric-Type-2
+
+ Metric-Type-2外部路由的开销等于AS外部开销
+
+| **Type** | **描述** | **开销计算** |
+| ---------------------- | -------------------------------------- | --------------------- |
+| Metric-Type-1 | 可信程度高 | AS内部开销+AS外部开销 |
+| Metric-Type-2 (缺省) | 可信程度低,AS外部开销远大于AS内部开销 | AS外部开销 |
+
+ +
+
+
+4.OSPF多区域项目实战
+
+ +
+
+
+第五节:OSPF特殊区域及其他特性
+
+一:Stub区域和Totally Stub区域
+
+1.网络规模变大引发的问题
+
+ OSPF路由器计算区域内、区域间、外部路由都需要依靠网络中的LSA,当网络规模变大时,设备的LSDB规模也变大,设备的路由计算变得更加吃力,造成设备性能浪费
+
+ +
+
+
+ +
+
+
+2.传输区域和末端区域
+
+ +
+ 传输区域(Transit Area):除了承载本区域发起的流量和访问本区域的流量外,还承载了源IP和目的IP都不属于本区域的流量,即“穿越型流量”,如本例中的Area 0
+
+ 末端区域(Stub Area):只承载本区域发起的流量和访问本区域的流量,如本例中的Area 1和Area 2
+
+
+
+ 传输区域(Transit Area):除了承载本区域发起的流量和访问本区域的流量外,还承载了源IP和目的IP都不属于本区域的流量,即“穿越型流量”,如本例中的Area 0
+
+ 末端区域(Stub Area):只承载本区域发起的流量和访问本区域的流量,如本例中的Area 1和Area 2
+
+3.Stub区域
+
+ Stub区域的ABR不向Stub区域内传播它接收到的AS外部路由,Stub区域中路由器的LSDB、路由表规模都会大大减小
+
+ 为保证Stub区域能够到达AS外部,Stub区域的ABR将生成一条缺省路由(使用3类LSA描述)
+
+**配置Stub区域时需要注意下列几点:**
+
+ 骨干区域不能被配置为Stub区域
+
+ Stub区域中的所有路由器都必须将该区域配置为Stub
+
+ Stub区域内不能引入也不接收AS外部路由
+
+ 虚连接不能穿越Stub区域
+
+ +
+**Stub区域的路由表及3类LSA**
+
+```shell
+[R3]ospf 1 router-id 3.3.3.3
+[R3-ospf-1]area 2
+[R3-ospf-1-area-0.0.0.2]stub
+R5相同
+```
+
+ R1作为ASBR引入多个外部网段,如果Area 2是普通区域,则R3将向该区域注入5类和4类LSA
+
+**当把Area 2配置为Stub区域后:**
+
+ R3不会将5类LSA和4类LSA注入Area 2
+
+ R3向Area 2发送用于描述缺省路由的3类LSA,Area 2内的路由器虽然不知道到达AS外部的具体路由,但是可以通过该默认路由到达AS外部
+
+```shell
+display ospf lsdb
+ OSPF Process 1 with Router ID 10.0.5.5
+ Link State Database
+ Area: 0.0.0.2
+ Type LinkState ID AdvRouter Metric
+ Sum-Net 0.0.0.0 10.0.3.3 1
+ Sum-Net 10.0.13.0 10.0.3.3 1
+ Sum-Net 10.0.24.0 10.0.3.3 3
+ Sum-Net 10.0.12.0 10.0.3.3 2
+不存在4、5类LSA,但描述区域间路由的3类LSA仍然存在
+```
+
+```shell
+display ospf routing
+
+ OSPF Process 1 with Router ID 10.0.5.5
+ Routing Tables
+ Routing for Network
+ Destination Cost Type NextHop AdvRouter Area
+ 10.0.35.0/24 1 Transit 10.0.35.5 10.0.5.5 0.0.0.2
+ 0.0.0.0/0 2 Inter-area 10.0.35.3 10.0.3.3 0.0.0.2
+ 10.0.12.0/24 3 Inter-area 10.0.35.3 10.0.3.3 0.0.0.2
+ 10.0.13.0/24 2 Inter-area 10.0.35.3 10.0.3.3 0.0.0.2
+ 10.0.24.0/24 4 Inter-area 10.0.35.3 10.0.3.3 0.0.0.2
+```
+
+
+
+**Stub区域的路由表及3类LSA**
+
+```shell
+[R3]ospf 1 router-id 3.3.3.3
+[R3-ospf-1]area 2
+[R3-ospf-1-area-0.0.0.2]stub
+R5相同
+```
+
+ R1作为ASBR引入多个外部网段,如果Area 2是普通区域,则R3将向该区域注入5类和4类LSA
+
+**当把Area 2配置为Stub区域后:**
+
+ R3不会将5类LSA和4类LSA注入Area 2
+
+ R3向Area 2发送用于描述缺省路由的3类LSA,Area 2内的路由器虽然不知道到达AS外部的具体路由,但是可以通过该默认路由到达AS外部
+
+```shell
+display ospf lsdb
+ OSPF Process 1 with Router ID 10.0.5.5
+ Link State Database
+ Area: 0.0.0.2
+ Type LinkState ID AdvRouter Metric
+ Sum-Net 0.0.0.0 10.0.3.3 1
+ Sum-Net 10.0.13.0 10.0.3.3 1
+ Sum-Net 10.0.24.0 10.0.3.3 3
+ Sum-Net 10.0.12.0 10.0.3.3 2
+不存在4、5类LSA,但描述区域间路由的3类LSA仍然存在
+```
+
+```shell
+display ospf routing
+
+ OSPF Process 1 with Router ID 10.0.5.5
+ Routing Tables
+ Routing for Network
+ Destination Cost Type NextHop AdvRouter Area
+ 10.0.35.0/24 1 Transit 10.0.35.5 10.0.5.5 0.0.0.2
+ 0.0.0.0/0 2 Inter-area 10.0.35.3 10.0.3.3 0.0.0.2
+ 10.0.12.0/24 3 Inter-area 10.0.35.3 10.0.3.3 0.0.0.2
+ 10.0.13.0/24 2 Inter-area 10.0.35.3 10.0.3.3 0.0.0.2
+ 10.0.24.0/24 4 Inter-area 10.0.35.3 10.0.3.3 0.0.0.2
+```
+
+ 4.Totally Stub区域
+
+ Totally Stub区域既不允许AS外部路由在本区域内传播,也不允许区域间路由在本区域内传播
+
+ Totally Stub区域内的路由器通过本区域ABR下发的缺省路由(使用3类LSA描述)到达其他区域,以及AS外部
+
+**配置Totally Stub区域时需要注意:**
+
+ 与Stub区域配置的区别在于,在ABR上需要追加no-summary关键字
+
+ +
+ Totally Stub区域访问其他区域及AS外部是通过默认路由实现的
+
+ AS外部、其他OSPF区域的拓扑及路由变化不会导致Totally Stub区域内的路由器进行路由重计算,减少了设备性能浪费
+
+
+
+ Totally Stub区域访问其他区域及AS外部是通过默认路由实现的
+
+ AS外部、其他OSPF区域的拓扑及路由变化不会导致Totally Stub区域内的路由器进行路由重计算,减少了设备性能浪费
+
+ +
+```shell
+[R3-ospf-1-area-0.0.0.2]stub no-summary
+[R5-ospf-1-area-0.0.0.2]stub
+```
+
+```shell
+display ospf lsdb
+ OSPF Process 1 with Router ID 10.0.5.5
+ Link State Database
+ Area: 0.0.0.2
+ Type LinkState ID AdvRouter Metric
+ Sum-Net 0.0.0.0 10.0.3.3 1
+```
+
+**当Area 2配置为Totally Stub区域后:**
+
+ R3不会将5类LSA和4类LSA注入Area 2
+
+ R3不会将3类LSA注入Area 2,但是会向该区域注入一条使用3类LSA描述的缺省路由
+
+ R5通过缺省路由到达AS外部网络和其他OSPF区域
+
+**注意:**
+
+ Stub区域、Totally Stub区域解决了末端区域维护过大LSDB带来的问题,但对于某些特定场景,它们并不是最佳解决方案
+
+
+
+```shell
+[R3-ospf-1-area-0.0.0.2]stub no-summary
+[R5-ospf-1-area-0.0.0.2]stub
+```
+
+```shell
+display ospf lsdb
+ OSPF Process 1 with Router ID 10.0.5.5
+ Link State Database
+ Area: 0.0.0.2
+ Type LinkState ID AdvRouter Metric
+ Sum-Net 0.0.0.0 10.0.3.3 1
+```
+
+**当Area 2配置为Totally Stub区域后:**
+
+ R3不会将5类LSA和4类LSA注入Area 2
+
+ R3不会将3类LSA注入Area 2,但是会向该区域注入一条使用3类LSA描述的缺省路由
+
+ R5通过缺省路由到达AS外部网络和其他OSPF区域
+
+**注意:**
+
+ Stub区域、Totally Stub区域解决了末端区域维护过大LSDB带来的问题,但对于某些特定场景,它们并不是最佳解决方案
+
+二:NSSA区域和Totally NSSA区域
+
+1.Stub区域与Totally Stub区域存在的问题
+
+ OSPF规定Stub区域是不能引入外部路由的,这样可以避免大量外部路由引入造成设备资源消耗
+
+ 对于既需要引入外部路由又要避免外部路由带来的资源消耗的场景,Stub和Totally Stub区域就不能满足需求了
+
+ +
+
+
+2.NSSA区域与Totally NSSA区域
+
+ NSSA区域能够引入外部路由,同时又不会学习来自OSPF网络其它区域引入的外部路由
+
+ Totally NSSA与NSSA区域的配置区别在于前者在ABR上需要追加no-summary关键字
+
+ +
+**NSSA区域能够引入外部路由,同时又不会学习来自OSPF网络其它区域的外部路由**
+
+ 7类LSA是为了支持NSSA区域而新增的一种LSA类型,用于描述NSSA区域引入的外部路由信息。NSSA区域的ASBR将外部路由引入该区域后,使用7类LSA描述这些路由
+
+ 7类LSA的扩散范围仅限于始发NSSA区域,7类LSA不会被注入到普通区域
+
+ NSSA区域的ABR会将7类LSA转化为5类LSA,并将该LSA注入到骨干区域,从而在整个OSPF域内泛洪
+
+ NSSA区域的ABR会阻挡其他区域引入的外部路由引入本区域,即NSSA区域内不会存在4类及5类LSA,为了让NSSA区域内的路由器能够通过骨干区域到达AS外部,NSSA区域的ABR会自动向该区域注入一条缺省路由,该路由采用7类LSA描述
+
+
+
+**NSSA区域能够引入外部路由,同时又不会学习来自OSPF网络其它区域的外部路由**
+
+ 7类LSA是为了支持NSSA区域而新增的一种LSA类型,用于描述NSSA区域引入的外部路由信息。NSSA区域的ASBR将外部路由引入该区域后,使用7类LSA描述这些路由
+
+ 7类LSA的扩散范围仅限于始发NSSA区域,7类LSA不会被注入到普通区域
+
+ NSSA区域的ABR会将7类LSA转化为5类LSA,并将该LSA注入到骨干区域,从而在整个OSPF域内泛洪
+
+ NSSA区域的ABR会阻挡其他区域引入的外部路由引入本区域,即NSSA区域内不会存在4类及5类LSA,为了让NSSA区域内的路由器能够通过骨干区域到达AS外部,NSSA区域的ABR会自动向该区域注入一条缺省路由,该路由采用7类LSA描述
+
+3.NSSA区域与Totally NSSA区域的LSDB
+
+
+
+
+
+```shell
+[R3-ospf-1-area-0.0.0.2]nssa
+[R5-ospf-1-area-0.0.0.2]nssa
+[R5-ospf-1]import-route direct
+```
+
+ 场景1(将Area 2配置为NSSA区域):当R5将外部路由192.168.3.0/24引入NSSA区域时,R5作为ASBR生成7类LSA在Area 2内泛洪;R3生成使用7类LSA描述的缺省路由注入Area 2,Area 2内的路由器依然会收到R3注入的3类LSA,并计算出到达其他区域的区域间路由
+
+ 场景2(将Area2配置为Totally NSSA区域):Totally NSSA区域和NSSA区域类似,只是Totally NSSA区域的ABR会阻挡3类LSA进入该区域,因此在场景2中,R3不会将区域间路由注入Area 2,故而在R5的LSDB中,仅会看到一条描述缺省路由的3类LSA
+
+4.OSPF LSA回顾
+
+| **类型** | **名称** | **描述** |
+| -------- | ---------------------------------- | ------------------------------------------------------------ |
+| 1 | 路由器LSA(Router LSA) | 每个设备都会产生,描述了设备的链路状态和开销,该LSA只能在接口所属的区域内泛洪 |
+| 2 | 网络LSA(Network LSA) | 由DR产生,描述该DR所接入的MA网络中所有与之形成邻接关系的路由器,以及DR自己。该LSA只能在接口所属区域内泛洪 |
+| 3 | 网络汇总LSA(Network Summary LSA) | 由ABR产生,描述区域内某个网段的路由,该类LSA主要用于区域间路由的传递 |
+| 4 | ASBR汇总LSA(ASBR Summary LSA) | 由ABR产生,描述到ASBR的路由,通告给除ASBR所在区域的其他相关区域。 |
+| 5 | AS外部LSA(AS External LSA) | 由ASBR产生,用于描述到达OSPF域外的路由 |
+| 7 | 非完全末梢区域LSA(NSSA LSA) | 由ASBR产生,用于描述到达OSPF域外的路由。NSSA LSA与AS外部LSA功能类似,但是泛洪范围不同。NSSA LSA只能在始发的NSSA内泛洪,并且不能直接进入Area0。NSSA的ABR会将7类LSA转换成5类LSA注入到Area0 |
+
+ 特殊区域的使用减小了设备的LSDB规模,从而减少设备性能浪费,且一定程度上也缩小了网络故障的影响范围
+
+5.路由器对LSA的处理原则
+
+ 如果收到的LSA本地没有,则更新LSDB并泛洪该LSA
+
+ 如果本地LSDB已存在该LSA,但是收到的更新,则更新LSDB并泛洪该LSA
+
+ 如果收到的LSA和LSDB中相同,则忽略,并终止泛洪
+
+ 如果收到的LSA损坏,例如Checksum错误,则不接收该LSA
+
+ +
+
+
+三:区域间路由汇总和外部路由汇总
+
+1.在ABR执行路由汇总
+
+ 路由汇总又被称为路由聚合,即是将一组前缀相同的路由汇聚成一条路由,从而达到减小路由表规模以及优化设备资源利用率的目的,我们把汇聚之前的这组路由称为精细路由或明细路由,把汇聚之后的这条路由称为汇总路由或聚合路由
+
+**OSPF路由汇总的类型:**
+
+ 在ABR(**区域边界路由器**)执行路由汇总:对区域间的路由执行路由汇总
+
+ 在ASBR(**自治系统边界路由器**)执行路由汇总:对引入的外部路由执行路由汇总
+
+ +
+**注意:**
+
+区域边界路由器ABR(Area Border Routers):
+
+ 该类路由器可以同时属于两个以上的区域,但其中一个必须是骨干区域(area 0)
+
+ ABR用来连接骨干区域和非骨干区域,可以是实际连接,也可以是虚连接
+
+骨干路由器(Backbong Routers)
+
+ 该类路由器属于骨干区域(area 0)。只维护骨干区域的LSDB
+
+ OSPF中,所有非骨干区域之间的信息都要通过骨干区域进行中转
+
+ 因此,所有的ABR和位于Area0的内部路由器都是骨干路由器
+
+自治系统边界路由器ASBR(AS Boundary Routers)
+
+ 与其他AS交换路由信息的路由器称为ASBR。 使用了多种路由协议
+
+ 只要一台OSPF路由器引入了外部路由的信息,他就称为了ASBR
+
+ 它有可能是ABR,区域路由器,不一定位于AS边界
+
+**汇总前:**
+
+```
+display ospf lsdb
+ area 0
+Type LinkState ID AdvRouter
+Sum-Net 172.16.0.0 10.0.2.2
+Sum-Net 172.16.1.0 10.0.2.2
+Sum-Net 172.16.2.0 10.0.2.2
+Sum-Net 172.16.3.0 10.0.2.2
+Sum-Net 172.16.4.0 10.0.2.2
+Sum-Net 172.16.5.0 10.0.2.2
+Sum-Net 172.16.6.0
+```
+
+**汇总后:**
+
+```
+display ospf lsdb
+ area 0
+Type LinkState ID AdvRouter
+Sum-Net 172.16.0.0 10.0.2.2
+```
+
+**注意:**
+
+ 执行路由汇总后,ABR R2只向Area 0通告汇总路由172.16.0.0/21
+
+ 明细路由对应的网段如果产生翻动(Up/Down),该拓扑变更造成的影响将被限制在Area 1内
+
+
+
+**注意:**
+
+区域边界路由器ABR(Area Border Routers):
+
+ 该类路由器可以同时属于两个以上的区域,但其中一个必须是骨干区域(area 0)
+
+ ABR用来连接骨干区域和非骨干区域,可以是实际连接,也可以是虚连接
+
+骨干路由器(Backbong Routers)
+
+ 该类路由器属于骨干区域(area 0)。只维护骨干区域的LSDB
+
+ OSPF中,所有非骨干区域之间的信息都要通过骨干区域进行中转
+
+ 因此,所有的ABR和位于Area0的内部路由器都是骨干路由器
+
+自治系统边界路由器ASBR(AS Boundary Routers)
+
+ 与其他AS交换路由信息的路由器称为ASBR。 使用了多种路由协议
+
+ 只要一台OSPF路由器引入了外部路由的信息,他就称为了ASBR
+
+ 它有可能是ABR,区域路由器,不一定位于AS边界
+
+**汇总前:**
+
+```
+display ospf lsdb
+ area 0
+Type LinkState ID AdvRouter
+Sum-Net 172.16.0.0 10.0.2.2
+Sum-Net 172.16.1.0 10.0.2.2
+Sum-Net 172.16.2.0 10.0.2.2
+Sum-Net 172.16.3.0 10.0.2.2
+Sum-Net 172.16.4.0 10.0.2.2
+Sum-Net 172.16.5.0 10.0.2.2
+Sum-Net 172.16.6.0
+```
+
+**汇总后:**
+
+```
+display ospf lsdb
+ area 0
+Type LinkState ID AdvRouter
+Sum-Net 172.16.0.0 10.0.2.2
+```
+
+**注意:**
+
+ 执行路由汇总后,ABR R2只向Area 0通告汇总路由172.16.0.0/21
+
+ 明细路由对应的网段如果产生翻动(Up/Down),该拓扑变更造成的影响将被限制在Area 1内
+
+2.在ASBR执行路由汇总
+
+ 在ASBR配置路由汇总后,ASBR将对自己所引入的外部路由进行汇总
+
+ NSSA区域的ASBR也可以对引入NSSA区域的外部路由进行汇总
+
+ 在NSSA区域中,ABR执行7类LSA转化成5类LSA动作,此时它也是ASBR。若配置路由汇总,则对由7类LSA转化成的5类LSA进行汇总
+
+ +
+
+
+四:OSPF协议特性
+
+1.Silent-Interface
+
+ 通过Silent-Interface的配置,增强OSPF的组网适应能力,减少系统资源的消耗
+
+**Silent-Interface有以下特性:**
+
+ Silent-Interface不会接收和发送OSPF报文
+
+ Silent-Interface的直连路由仍可以发布出去
+
+ +
+```shell
+display ospf interface GigabitEthernet 0/0/1
+
+ OSPF Process 1 with Router ID 10.0.1.1
+Interface: 10.0.13.1 (GigabitEthernet0/0/1)
+ Cost: 1 State: Waiting Type: Broadcast MTU: 1500
+ Priority: 1
+ Designated Router: 0.0.0.0
+ Backup Designated Router: 0.0.0.0
+ Timers: Hello 10 , Dead 40 , Poll 120 , Retransmit 5 , Transmit Delay 1
+ Silent interface, No hellos
+```
+
+**注意:**
+
+ R1的GE0/0/1接口在OSPF network命令的网段范围内
+
+ 到达该接口的路由将被通告到OSPF,使得其他设备能够访问Server
+
+ 由于该接口上未连接任何其他OSPF路由器,因此管理员将该接口配置为Silent-Interface,该接口将不再收发Hello报文,从而避免了对Server的性能降低
+
+
+
+```shell
+display ospf interface GigabitEthernet 0/0/1
+
+ OSPF Process 1 with Router ID 10.0.1.1
+Interface: 10.0.13.1 (GigabitEthernet0/0/1)
+ Cost: 1 State: Waiting Type: Broadcast MTU: 1500
+ Priority: 1
+ Designated Router: 0.0.0.0
+ Backup Designated Router: 0.0.0.0
+ Timers: Hello 10 , Dead 40 , Poll 120 , Retransmit 5 , Transmit Delay 1
+ Silent interface, No hellos
+```
+
+**注意:**
+
+ R1的GE0/0/1接口在OSPF network命令的网段范围内
+
+ 到达该接口的路由将被通告到OSPF,使得其他设备能够访问Server
+
+ 由于该接口上未连接任何其他OSPF路由器,因此管理员将该接口配置为Silent-Interface,该接口将不再收发Hello报文,从而避免了对Server的性能降低
+
+2.OSPF报文认证
+
+ OSPF支持报文认证功能,只有通过认证的OSPF报文才能被接收
+
+**路由器支持两种OSPF报文认证方式,当两种认证方式都存在时,优先使用接口认证方式:**
+
+ 区域认证方式:一个OSPF区域中所有的路由器在该区域下的认证模式和口令必须一致
+
+ 接口认证方式:相邻路由器直连接口下的认证模式和口令必须一致
+
+ +
+```shell
+[R2]interface GigabitEthernet 0/0/1
+[R2-GigabitEthernet0/0/1]ospf authentication-mode md5 1 cipher Huawei
+```
+
+```shell
+[R2]ospf
+[R2-ospf-1]area 0
+[R2-ospf-1-area-0.0.0.0]authentication-mode simple cipher Huawei
+```
+
+**区域视图下,配置OSPF区域的认证模式**
+
+ 执行命令authentication-mode simple [ plain plain-text | [ cipher ] cipher-text ],配置OSPF区域的认证模式
+
+ plain表示明文口令类型
+
+ cipher表示密文口令类型。对于MD5/HMAC-MD5认证模式,当此参数缺省时,默认为cipher类型
+
+ 配置接口认证方式。
+
+ 执行命令ospf authentication-mode simple [ plain plain-text | [ cipher ] cipher-text ],配置OSPF接口的认证模式
+
+
+```shell
+[R2]interface GigabitEthernet 0/0/1
+[R2-GigabitEthernet0/0/1]ospf authentication-mode md5 1 cipher Huawei
+```
+
+```shell
+[R2]ospf
+[R2-ospf-1]area 0
+[R2-ospf-1-area-0.0.0.0]authentication-mode simple cipher Huawei
+```
+
+**区域视图下,配置OSPF区域的认证模式**
+
+ 执行命令authentication-mode simple [ plain plain-text | [ cipher ] cipher-text ],配置OSPF区域的认证模式
+
+ plain表示明文口令类型
+
+ cipher表示密文口令类型。对于MD5/HMAC-MD5认证模式,当此参数缺省时,默认为cipher类型
+
+ 配置接口认证方式。
+
+ 执行命令ospf authentication-mode simple [ plain plain-text | [ cipher ] cipher-text ],配置OSPF接口的认证模式
+