|
|
|
|
@ -0,0 +1,171 @@
|
|
|
|
|
<h1><center>深入理解容器Docker中的Cgroups</center></h1>
|
|
|
|
|
|
|
|
|
|
**作者:行癫(盗版必究)**
|
|
|
|
|
|
|
|
|
|
------
|
|
|
|
|
|
|
|
|
|
#### 1、Cgroups 是什么
|
|
|
|
|
|
|
|
|
|
**官方定义**:Cgroups 是 Linux 内核提供的一种机制,用来限制、记录、隔离进程组所使用的资源(CPU、内存、磁盘 I/O、网络等)
|
|
|
|
|
|
|
|
|
|
**通俗理解**:它就像一个“配额管理器”或“资源闸门”,用来规定容器能用多少资源,防止“一个人吃光一桌菜”的情况
|
|
|
|
|
|
|
|
|
|
#### 2、生活中的类比
|
|
|
|
|
|
|
|
|
|
想象一个自助餐厅
|
|
|
|
|
|
|
|
|
|
**没有 Cgroups**:
|
|
|
|
|
|
|
|
|
|
每个人(进程)都可以随便拿菜(系统资源),结果有些人很能吃(比如内存泄漏的进程),把菜全拿走了,其他人饿肚子(服务器卡死)
|
|
|
|
|
|
|
|
|
|
**有了 Cgroups**:
|
|
|
|
|
|
|
|
|
|
A 同学最多拿 2个汉堡(CPU 限制)
|
|
|
|
|
|
|
|
|
|
B 同学最多只准吃 500g 米饭(内存限制)
|
|
|
|
|
|
|
|
|
|
C 同学一次只能舀 1碗汤(I/O 限制)
|
|
|
|
|
|
|
|
|
|
这样,每个人都能吃到,不会有人霸占资源
|
|
|
|
|
|
|
|
|
|
总结:在 Docker 容器里,Cgroups 就是餐厅的“取餐规则”
|
|
|
|
|
|
|
|
|
|
#### 3、Cgroups控制的资源类型
|
|
|
|
|
|
|
|
|
|
**CPU**:限制容器使用 CPU 的比例或核心数
|
|
|
|
|
|
|
|
|
|
👉 类比:一个人不能霸占整个烤肉炉,只能用 30% 的火力
|
|
|
|
|
|
|
|
|
|
**内存**:限制容器能用多少内存,超过就会被 OOM-Killer 杀掉
|
|
|
|
|
|
|
|
|
|
👉 类比:吃饭的盘子大小有限,超过盘子边缘就不能再装
|
|
|
|
|
|
|
|
|
|
**I/O**:限制容器的磁盘读写速度
|
|
|
|
|
|
|
|
|
|
👉 类比:打饭窗口一次只能舀多少汤,不能狂灌
|
|
|
|
|
|
|
|
|
|
**网络**(通过 TC 等):限制带宽
|
|
|
|
|
|
|
|
|
|
👉 类比:每个人过安检的通道是限流的,不可能冲在前面挤爆
|
|
|
|
|
|
|
|
|
|
#### 4、Docker 与 Cgroups 的关系
|
|
|
|
|
|
|
|
|
|
Docker 自己并不实现资源隔离,而是调用 Linux 内核的功能
|
|
|
|
|
|
|
|
|
|
**Namespace** → 给容器提供“独立环境”,比如独立的进程树、网络、文件系统
|
|
|
|
|
|
|
|
|
|
**Cgroups** → 控制和分配容器能用多少资源
|
|
|
|
|
|
|
|
|
|
👉 可以把 Namespace 看作“墙壁”,Cgroups 看作“饭票”
|
|
|
|
|
|
|
|
|
|
Docker 本身只是“餐厅管理软件”,真正发力的是内核的 Namespace 和 Cgroups
|
|
|
|
|
|
|
|
|
|
#### 5、应用案例
|
|
|
|
|
|
|
|
|
|
##### 限制CPU share:
|
|
|
|
|
|
|
|
|
|
CPU 资源:
|
|
|
|
|
|
|
|
|
|
主机上的进程会通过时间分片机制使用 CPU,CPU 的量化单位是频率,也就是每秒钟能执行的运算次数。为容器限制 CPU 资源并不能改变 CPU 的运行频率,而是改变每个容器能使用的 CPU 时间片。理想状态下,CPU 应该一直处于运算状态(并且进程需要的计算量不会超过 CPU 的处理能力)
|
|
|
|
|
|
|
|
|
|
Docker 限制 CPU Share:
|
|
|
|
|
|
|
|
|
|
docker 允许用户为每个容器设置一个数字,代表容器的 CPU share,默认情况下每个容器的 share 是 1024。这个 share 是相对的,本身并不能代表任何确定的意义。当主机上有多个容器运行时,每个容器占用的 CPU 时间比例为它的 share 在总额中的比例。docker 会根据主机上运行的容器和进程动态调整每个容器使用 CPU 的时间比例
|
|
|
|
|
|
|
|
|
|
例子:
|
|
|
|
|
|
|
|
|
|
如果主机上有两个一直使用 CPU 的容器(为了简化理解,不考虑主机上其他进程),其 CPU share 都是 1024,那么两个容器 CPU 使用率都是 50%;如果把其中一个容器的 share 设置为 512,那么两者 CPU 的使用率分别为 67% 和 33%;如果删除 share 为 1024 的容器,剩下来容器的 CPU 使用率将会是 100%
|
|
|
|
|
|
|
|
|
|
好处:
|
|
|
|
|
|
|
|
|
|
能保证 CPU 尽可能处于运行状态,充分利用 CPU 资源,而且保证所有容器的相对公平
|
|
|
|
|
|
|
|
|
|
缺点:
|
|
|
|
|
|
|
|
|
|
无法指定容器使用 CPU 的确定值
|
|
|
|
|
|
|
|
|
|
设置 CPU share 的参数:
|
|
|
|
|
|
|
|
|
|
-c --cpu-shares,它的值是一个整数
|
|
|
|
|
|
|
|
|
|
我的机器是 4 核 CPU,因此运行一个stress容器,使用 stress 启动 4 个进程来产生计算压力:
|
|
|
|
|
|
|
|
|
|
```shell
|
|
|
|
|
# docker pull progrium/stress
|
|
|
|
|
# yum install htop -y
|
|
|
|
|
# docker run --rm -it progrium/stress --cpu 4
|
|
|
|
|
stress: info: [1] dispatching hogs: 4 cpu, 0 io, 0 vm, 0 hdd
|
|
|
|
|
stress: dbug: [1] using backoff sleep of 12000us
|
|
|
|
|
stress: dbug: [1] --> hogcpu worker 4 [7] forked
|
|
|
|
|
stress: dbug: [1] using backoff sleep of 9000us
|
|
|
|
|
stress: dbug: [1] --> hogcpu worker 3 [8] forked
|
|
|
|
|
stress: dbug: [1] using backoff sleep of 6000us
|
|
|
|
|
stress: dbug: [1] --> hogcpu worker 2 [9] forked
|
|
|
|
|
stress: dbug: [1] using backoff sleep of 3000us
|
|
|
|
|
stress: dbug: [1] --> hogcpu worker 1 [10] forked
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
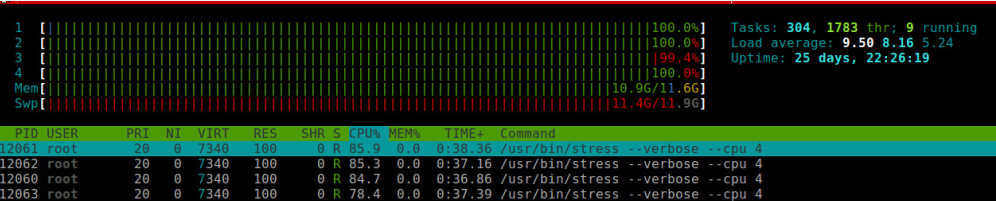
在另外一个 terminal 使用 htop 查看资源的使用情况:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
上图中看到,CPU 四个核资源都达到了 100%。四个 stress 进程 CPU 使用率没有达到 100% 是因为系统中还有其他机器在运行
|
|
|
|
|
|
|
|
|
|
为了比较,另外启动一个 share 为 512 的容器
|
|
|
|
|
|
|
|
|
|
```shell
|
|
|
|
|
# docker run --rm -it -c 512 progrium/stress --cpu 4
|
|
|
|
|
stress: info: [1] dispatching hogs: 4 cpu, 0 io, 0 vm, 0 hdd
|
|
|
|
|
stress: dbug: [1] using backoff sleep of 12000us
|
|
|
|
|
stress: dbug: [1] --> hogcpu worker 4 [6] forked
|
|
|
|
|
stress: dbug: [1] using backoff sleep of 9000us
|
|
|
|
|
stress: dbug: [1] --> hogcpu worker 3 [7] forked
|
|
|
|
|
stress: dbug: [1] using backoff sleep of 6000us
|
|
|
|
|
stress: dbug: [1] --> hogcpu worker 2 [8] forked
|
|
|
|
|
stress: dbug: [1] using backoff sleep of 3000us
|
|
|
|
|
stress: dbug: [1] --> hogcpu worker 1 [9] forked
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
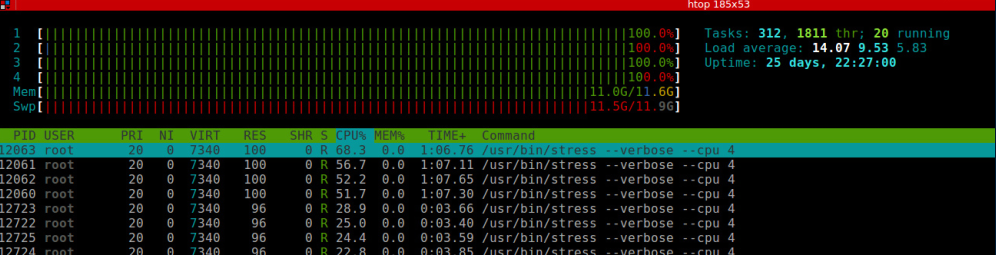
因为默认情况下,容器的 CPU share 为 1024,所以这两个容器的 CPU 使用率应该大致为 2:1,下面是启动第二个容器之后的监控截图:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
两个容器分别启动了四个 stress 进程,第一个容器 stress 进程 CPU 使用率都在 54% 左右,第二个容器 stress 进程 CPU 使用率在 25% 左右,比例关系大致为 2:1,符合之前的预期
|
|
|
|
|
|
|
|
|
|
##### 限制容器的 CPU 核数:
|
|
|
|
|
|
|
|
|
|
-c --cpu-shares 参数只能限制容器使用 CPU 的比例,或者说优先级,无法确定地限制容器使用 CPU 的具体核数;从 1.13 版本之后,docker 提供了 --cpus 参数可以限定容器能使用的 CPU 核数。这个功能可以让我们更精确地设置容器 CPU 使用量,是一种更容易理解也因此更常用的手段;-cpus 后面跟着一个浮点数,代表容器最多使用的核数,可以精确到小数点二位,也就是说容器最小可以使用 0.01 核 CPU
|
|
|
|
|
|
|
|
|
|
限制容器只能使用 1.5 核数 CPU
|
|
|
|
|
|
|
|
|
|
```shell
|
|
|
|
|
# docker run --rm -it --cpus 1.5 progrium/stress --cpu 3
|
|
|
|
|
stress: info: [1] dispatching hogs: 3 cpu, 0 io, 0 vm, 0 hdd
|
|
|
|
|
stress: dbug: [1] using backoff sleep of 9000us
|
|
|
|
|
stress: dbug: [1] --> hogcpu worker 3 [7] forked
|
|
|
|
|
stress: dbug: [1] using backoff sleep of 6000us
|
|
|
|
|
stress: dbug: [1] --> hogcpu worker 2 [8] forked
|
|
|
|
|
stress: dbug: [1] using backoff sleep of 3000us
|
|
|
|
|
stress: dbug: [1] --> hogcpu worker 1 [9] forked
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
在容器里启动三个 stress 来跑 CPU 压力,如果不加限制,这个容器会导致 CPU 的使用率为 300% 左右(也就是说会占用三个核的计算能力)。实际的监控如下图:
|
|
|
|
|
|
|
|
|
|

|
|
|
|
|
|
|
|
|
|
可以看到,每个 stress 进程 CPU 使用率大约在 50%,总共的使用率为 150%,符合 1.5 核的设置
|
|
|
|
|
|
|
|
|
|
如果设置的 --cpus 值大于主机的 CPU 核数,docker 会直接报错:
|
|
|
|
|
|
|
|
|
|
```shell
|
|
|
|
|
# docker run --rm -it --cpus 8 progrium/stress --cpu 3
|
|
|
|
|
docker: Error response from daemon: Range of CPUs is from 0.01 to 4.00, as there are only 4 CPUs available.
|
|
|
|
|
See 'docker run --help'.
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
如果多个容器都设置了 --cpus ,并且它们之和超过主机的 CPU 核数,并不会导致容器失败或者退出,这些容器之间会竞争使用 CPU,具体分配的 CPU 数量取决于主机运行情况和容器的 CPU share 值。也就是说 --cpus 只能保证在 CPU 资源充足的情况下容器最多能使用的 CPU 数,docker 并不能保证在任何情况下容器都能使用这么多的 CPU(因为这根本是不可能的)
|
|
|
|
|
|
|
|
|
|
#### 6、Cgroups 工作原理的图
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|