|
|
|
|
@ -1,349 +0,0 @@
|
|
|
|
|
<h1><center>日志中心集群</center></h1>
|
|
|
|
|
|
|
|
|
|
作者:行癫(盗版必究)
|
|
|
|
|
|
|
|
|
|
------
|
|
|
|
|
|
|
|
|
|
## 一:组件介绍
|
|
|
|
|
|
|
|
|
|
#### 1.Elasticsearch
|
|
|
|
|
|
|
|
|
|
主要用来日志存储
|
|
|
|
|
|
|
|
|
|
是一个基于Lucene的搜索服务器。提供搜集、分析、存储数据三大功能。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
|
|
|
|
|
|
|
|
|
|
#### 2.Logstash
|
|
|
|
|
|
|
|
|
|
主要用来日志的搜集
|
|
|
|
|
|
|
|
|
|
主要是用来日志的搜集、分析、过滤日志的工具。用于管理日志和事件的工具,你可以用它去收集日志、转换日志、解析日志并将他们作为数据提供给其它模块调用,例如搜索、存储等。
|
|
|
|
|
|
|
|
|
|
#### 3.Kibana
|
|
|
|
|
|
|
|
|
|
主要用于日志的展示
|
|
|
|
|
|
|
|
|
|
是一个优秀的前端日志展示框架,它可以非常详细的将日志转化为各种图表,为用户提供强大的数据可视化支持,它能够搜索、展示存储在 Elasticsearch 中索引数据。使用它可以很方便的用图表、表格、地图展示和分析数据。
|
|
|
|
|
|
|
|
|
|
#### 4.Kafka
|
|
|
|
|
|
|
|
|
|
是一种高吞吐量的分布式发布订阅消息系统。具有峰值处理能力,使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。
|
|
|
|
|
|
|
|
|
|
#### 5.Filebeat
|
|
|
|
|
|
|
|
|
|
隶属于Beats,轻量级数据收集引擎。基于原先 Logstash-fowarder 的源码改造出来。换句话说:Filebeat就是新版的 Logstash-fowarder,也会是 ELK Stack 在 Agent 的第一选择;常见的Beat有:
|
|
|
|
|
|
|
|
|
|
Packetbeat(搜集网络流量数据)
|
|
|
|
|
|
|
|
|
|
Metricbeat(搜集系统、进程和文件系统级别的 CPU 和内存使用情况等数据)
|
|
|
|
|
|
|
|
|
|
Filebeat(搜集文件数据)
|
|
|
|
|
|
|
|
|
|
Winlogbeat(搜集 Windows 事件日志数据)
|
|
|
|
|
|
|
|
|
|
#### 6.为什么会用到ELK
|
|
|
|
|
|
|
|
|
|
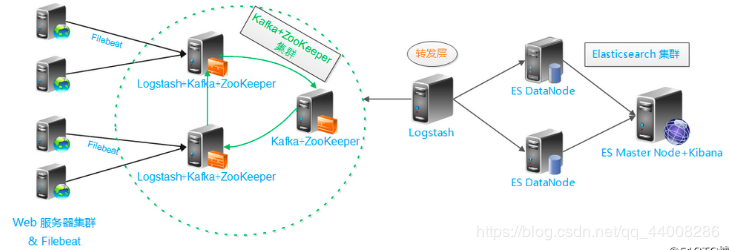
普通的日志分析场景:直接在日志文件中grep、awk就可以获得自己想要的信息,但在规模较大的场景中,此方法效率底下,面临问题包括日志量太大如何归档、文本搜索太慢、如何多纬度的查询。这样我们就需要集中化的日志管理,所有的服务器上的日志收集汇总。解决方案:建立集中式日志收集系统,将所有节点上的日志统一收集,管理,访问。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
## 二:集群构建
|
|
|
|
|
|
|
|
|
|
#### 1.架构
|
|
|
|
|
|
|
|
|
|
<img src="https://diandiange.oss-cn-beijing.aliyuncs.com/image-20240531093110260.png" alt="image-20240531093110260" style="zoom:100%;" />
|
|
|
|
|
|
|
|
|
|
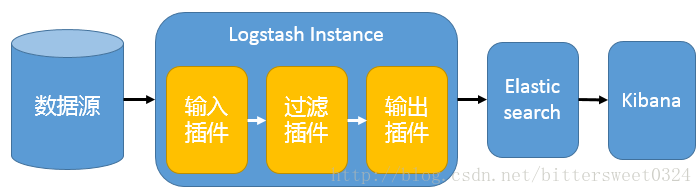
**基础架构**
|
|
|
|
|
|
|
|
|
|
单一的架构,logstash作为日志搜集器,从数据源采集数据,并对数据进行过滤,格式化处理,然后交由Elasticsearch存储,kibana对日志进行可视化处理
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
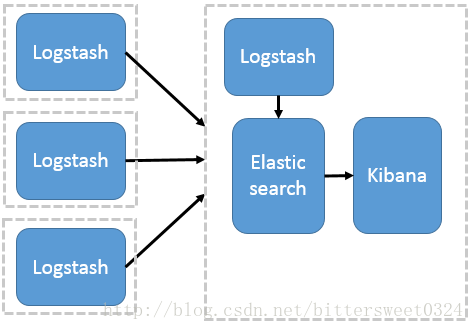
**多节点部署Logstash架构**
|
|
|
|
|
|
|
|
|
|
这种架构模式适合需要采集日志的客户端不多,且各服务端cpu,内存等资源充足的情况下。因为每个节点都安装Logstash, 非常消耗节点资源。其中,logstash作为日志搜集器,将每一台节点的数据发送到Elasticsearch上进行存储,再由kibana进行可视化分析。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
#### 2.版本说明
|
|
|
|
|
|
|
|
|
|
Elasticsearch: 6.5.4
|
|
|
|
|
|
|
|
|
|
Logstash: 6.5.4
|
|
|
|
|
|
|
|
|
|
Kibana: 6.5.4
|
|
|
|
|
|
|
|
|
|
Kafka: 2.11-1
|
|
|
|
|
|
|
|
|
|
Filebeat: 6.5.4
|
|
|
|
|
|
|
|
|
|
#### 3.官网地址
|
|
|
|
|
|
|
|
|
|
官网地址:https://www.elastic.co
|
|
|
|
|
|
|
|
|
|
官网搭建:https://www.elastic.co/guide/index.html
|
|
|
|
|
|
|
|
|
|
#### 4.集群部署
|
|
|
|
|
|
|
|
|
|
系统类型:Centos7.x
|
|
|
|
|
|
|
|
|
|
节点IP:172.16.244.25、172.16.244.26、172.16.244.27
|
|
|
|
|
|
|
|
|
|
软件版本:jdk-8u121-linux-x64.tar.gz、elasticsearch-6.5.4.tar.gz
|
|
|
|
|
|
|
|
|
|
示例节点:172.16.244.25 ABC
|
|
|
|
|
|
|
|
|
|
##### node-1节点
|
|
|
|
|
|
|
|
|
|
安装配置jdk
|
|
|
|
|
|
|
|
|
|
```shell
|
|
|
|
|
[root@xingdian ~]# tar zxvf /usr/local/package/jdk-8u121-linux-x64.tar.gz -C /usr/local/
|
|
|
|
|
[root@xingdian ~]# mv /usr/local/jdk-8u121 /usr/local/java
|
|
|
|
|
[root@xingdian ~]# vim /etc/profile
|
|
|
|
|
JAVA_HOME=/usr/local/java
|
|
|
|
|
PATH=$JAVA_HOME/bin:$PATH
|
|
|
|
|
export JAVA_HOME PATH
|
|
|
|
|
[root@xingdian ~]# source /etc/profile
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
创建运行ES的普通用户
|
|
|
|
|
|
|
|
|
|
```shell
|
|
|
|
|
[root@xingdian ~]# useradd elsearch (useradd ela)
|
|
|
|
|
[root@xingdian ~]# echo "******" | passwd --stdin "elsearch"
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
安装配置ES
|
|
|
|
|
|
|
|
|
|
```shell
|
|
|
|
|
[root@xingdian ~]# tar zxvf /usr/local/package/elasticsearch-6.5.4.tar.gz -C /usr/local/
|
|
|
|
|
[root@xingdian ~]# vim /usr/local/elasticsearch-6.5.4/config/elasticsearch.yml
|
|
|
|
|
cluster.name: bjbpe01-elk
|
|
|
|
|
node.name: elk01
|
|
|
|
|
node.master: true
|
|
|
|
|
node.data: true
|
|
|
|
|
path.data: /data/elasticsearch/data
|
|
|
|
|
path.logs: /data/elasticsearch/logs
|
|
|
|
|
bootstrap.memory_lock: false
|
|
|
|
|
bootstrap.system_call_filter: false
|
|
|
|
|
network.host: 0.0.0.0
|
|
|
|
|
http.port: 9200
|
|
|
|
|
#discovery.zen.ping.unicast.hosts: ["172.16.244.26", "172.16.244.27"]
|
|
|
|
|
#discovery.zen.ping_timeout: 150s
|
|
|
|
|
#discovery.zen.fd.ping_retries: 10
|
|
|
|
|
#client.transport.ping_timeout: 60s
|
|
|
|
|
http.cors.enabled: true
|
|
|
|
|
http.cors.allow-origin: "*"
|
|
|
|
|
注意:如果是集群取消配置文件中的所有注释,并修改对应的参数
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
设置JVM堆大小
|
|
|
|
|
|
|
|
|
|
```shell
|
|
|
|
|
[root@xingdian ~]# sed -i 's/-Xms1g/-Xms4g/' /usr/local/elasticsearch-6.5.4/config/jvm.options
|
|
|
|
|
[root@xingdian ~]# sed -i 's/-Xmx1g/-Xmx4g/' /usr/local/elasticsearch-6.5.4/config/jvm.options
|
|
|
|
|
注意: 确保堆内存最小值(Xms)与最大值(Xmx)的大小相同,防止程序在运行时改变堆内存大小。 如果系统内存足够大,将堆内存最大和最小值设置为31G,因为有一个32G性能瓶颈问题。 堆内存大小不要超过系统内存的50%。
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
创建ES数据及日志存储目录
|
|
|
|
|
|
|
|
|
|
```shell
|
|
|
|
|
[root@xingdian ~]# mkdir -p /data/elasticsearch/data (/data/elasticsearch)
|
|
|
|
|
[root@xingdian ~]# mkdir -p /data/elasticsearch/logs (/log/elasticsearch)
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
修改安装目录及存储目录权限
|
|
|
|
|
|
|
|
|
|
```shell
|
|
|
|
|
[root@xingdian ~]# chown -R elsearch:elsearch /data/elasticsearch
|
|
|
|
|
[root@xingdian ~]# chown -R elsearch:elsearch /usr/local/elasticsearch-6.5.4
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
系统优化
|
|
|
|
|
|
|
|
|
|
```shell
|
|
|
|
|
修改/etc/security/limits.conf配置文件,将以下内容添加到配置文件中。(*表示所有用户)
|
|
|
|
|
* soft nofile 65536
|
|
|
|
|
* hard nofile 131072
|
|
|
|
|
* soft nproc 2048
|
|
|
|
|
* hard nproc 4096
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
增加最大内存映射数
|
|
|
|
|
|
|
|
|
|
```shell
|
|
|
|
|
[root@xingdian ~]# echo "vm.max_map_count=262144" >> /etc/sysctl.conf
|
|
|
|
|
[root@xingdian ~]# sysctl -p
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
启动ES
|
|
|
|
|
|
|
|
|
|
```shell
|
|
|
|
|
su - elsearch -c "cd /usr/local/elasticsearch-6.5.4 && nohup bin/elasticsearch &"
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
node-2节点的elasticsearch部署跟node-1相同
|
|
|
|
|
|
|
|
|
|
##### node-2节点
|
|
|
|
|
|
|
|
|
|
略
|
|
|
|
|
|
|
|
|
|
##### node-3节点
|
|
|
|
|
|
|
|
|
|
略
|
|
|
|
|
|
|
|
|
|
#### 5.配置文件
|
|
|
|
|
|
|
|
|
|
```shell
|
|
|
|
|
cluster.name 集群名称,各节点配成相同的集群名称。
|
|
|
|
|
node.name 节点名称,各节点配置不同。
|
|
|
|
|
node.master 指示某个节点是否符合成为主节点的条件。
|
|
|
|
|
node.data 指示节点是否为数据节点。数据节点包含并管理索引的一部分。
|
|
|
|
|
path.data 数据存储目录。
|
|
|
|
|
path.logs 日志存储目录。
|
|
|
|
|
bootstrap.memory_lock 内存锁定,是否禁用交换。
|
|
|
|
|
bootstrap.system_call_filter 系统调用过滤器。
|
|
|
|
|
network.host 绑定节点IP。
|
|
|
|
|
http.port rest api端口。
|
|
|
|
|
discovery.zen.ping.unicast.hosts 提供其他 Elasticsearch 服务节点的单点广播发现功能。
|
|
|
|
|
discovery.zen.ping_timeout 节点在发现过程中的等待时间。
|
|
|
|
|
discovery.zen.fd.ping_retries 节点发现重试次数。
|
|
|
|
|
http.cors.enabled 是否允许跨源 REST 请求,用于允许head插件访问ES。
|
|
|
|
|
http.cors.allow-origin 允许的源地址。
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
#### 6.浏览器访问测试
|
|
|
|
|
|
|
|
|
|
注意:默认端口9200
|
|
|
|
|
|
|
|
|
|

|
|
|
|
|
|
|
|
|
|
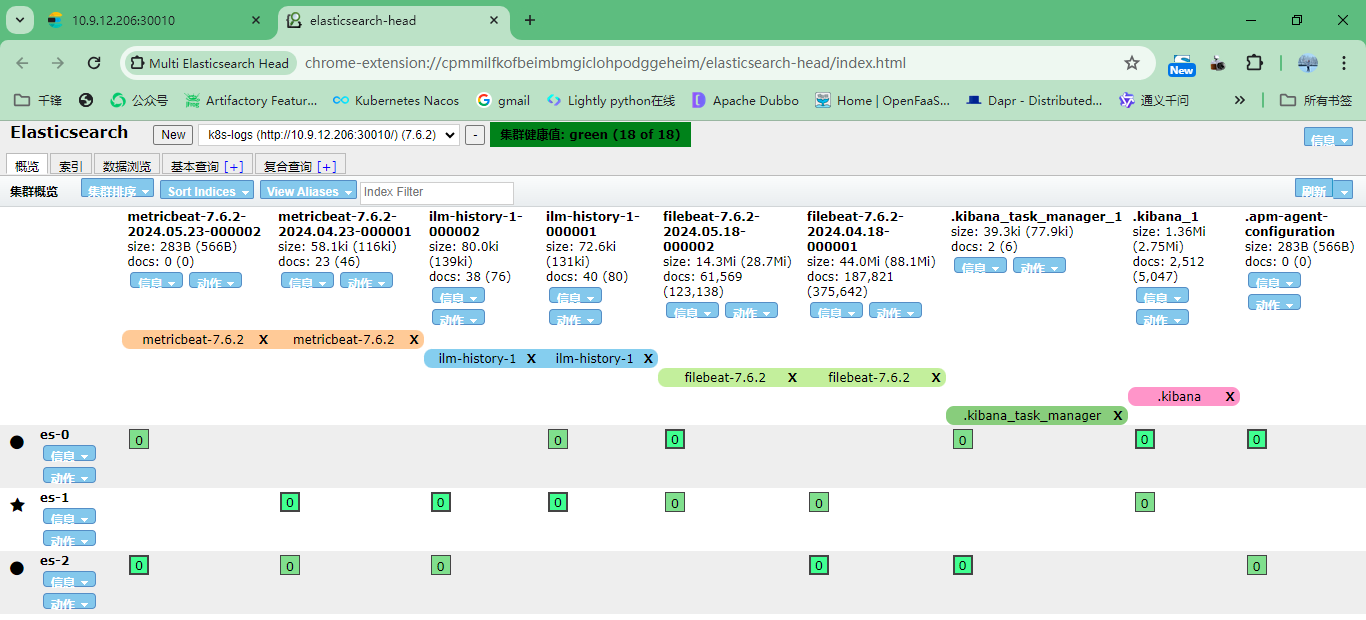
7.安装head插件
|
|
|
|
|
|
|
|
|
|
注意:使用google或者edge浏览器对应的head插件即可
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
#### 7.模拟数据插入
|
|
|
|
|
|
|
|
|
|
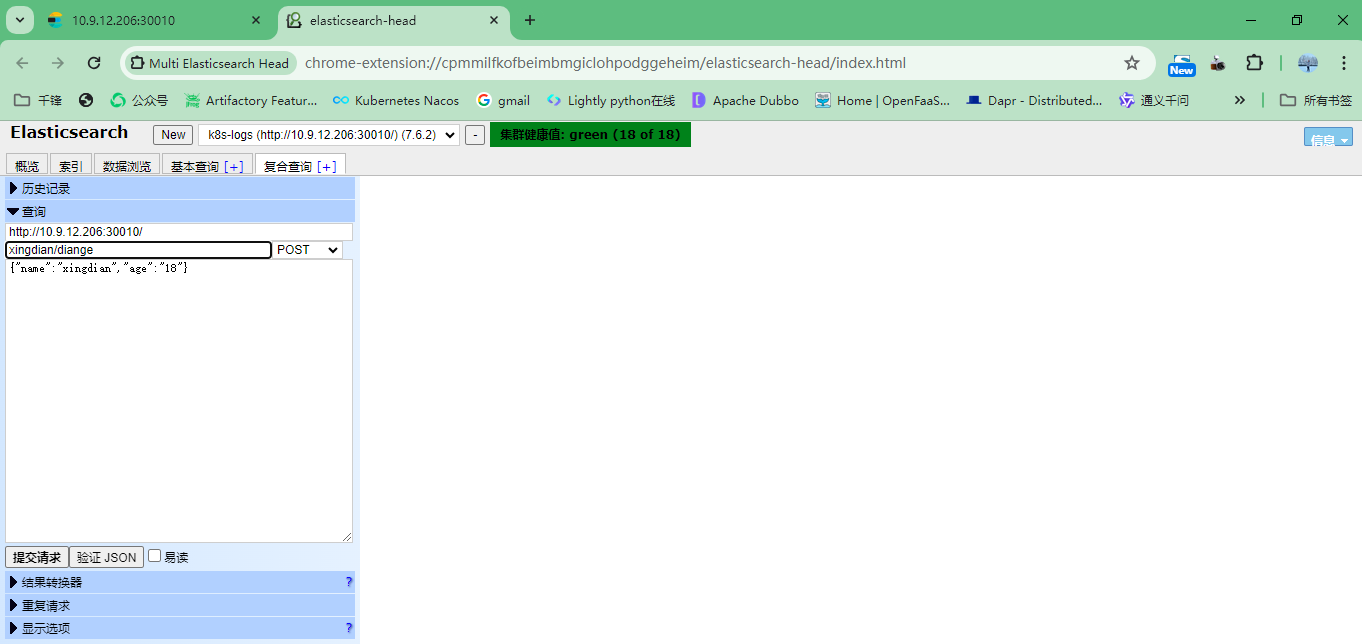
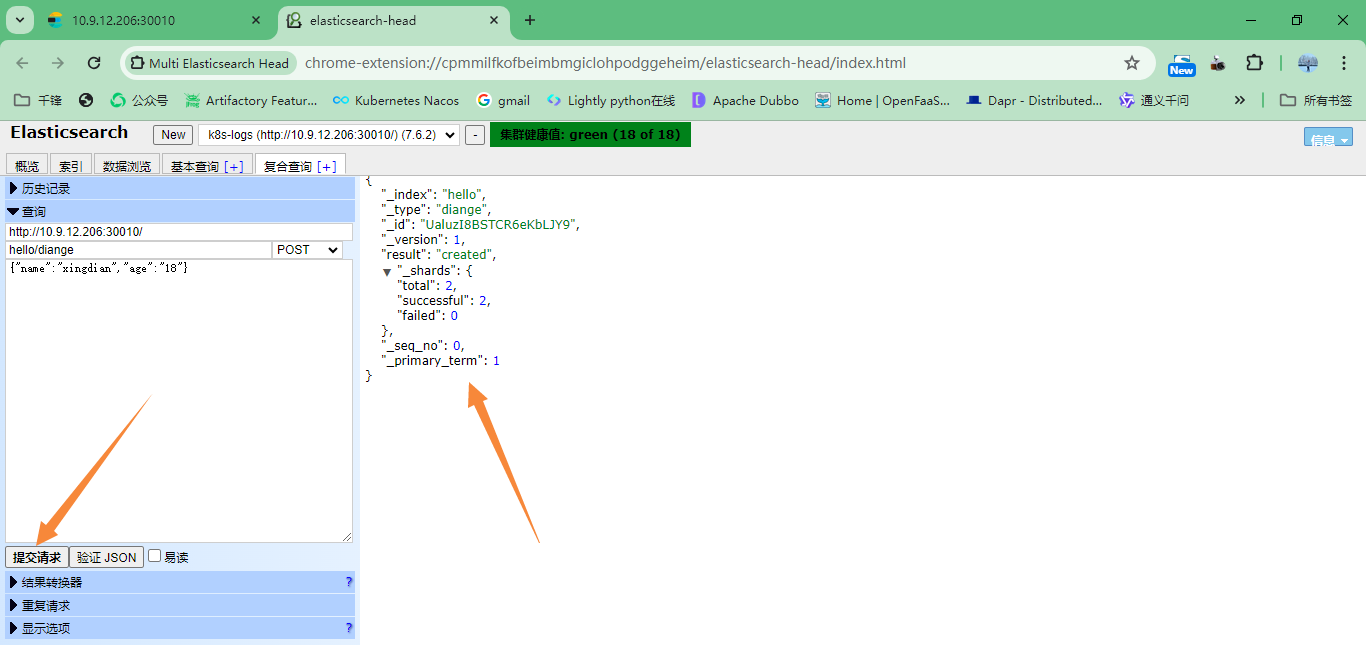
注意:索引名字:xingdian/test 数据: {"user":"xingdian","mesg":"hello world"}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|

|
|
|
|
|
|
|
|
|
|
## 二:基本概念
|
|
|
|
|
|
|
|
|
|
#### 1.ES与传统数据的区别
|
|
|
|
|
|
|
|
|
|
一个ES集群可以包含多个索引(数据库),每个索引又包含了很多类型(表),类型中包含了很多文档(行),每个文档使用 JSON 格式存储数据,包含了很多字段(列)。
|
|
|
|
|
|
|
|
|
|
| 关系型数据库 | Elasticsearch |
|
|
|
|
|
| :-------------: | :-----------------: |
|
|
|
|
|
| 数据库>表>行>列 | 索引>类型>文档>字段 |
|
|
|
|
|
|
|
|
|
|
#### 2.基本概念
|
|
|
|
|
|
|
|
|
|
##### 索引(index)
|
|
|
|
|
|
|
|
|
|
ES将数据存储于一个或多个索引中。类比传统的关系型数据库领域来说,索引相当于SQL中的一个数据库,索引由其名称(必须为全小写字符)进行标识。一个ES集群中可以按需创建任意数目的索引。
|
|
|
|
|
|
|
|
|
|
##### 类型(type)
|
|
|
|
|
|
|
|
|
|
类型是索引内部的逻辑分区(category/partition),一个索引内部可定义一个或多个类型(type)。类比传统的关系型数据库领域来说,类型相当于“表”。
|
|
|
|
|
|
|
|
|
|
##### 文档(document)
|
|
|
|
|
|
|
|
|
|
文档是索引和搜索的原子单位,它是包含了一个或多个域(Field)的容器,每个域拥有一个名字及一个或多个值,有多个值的域通常称为“多值域”,文档基于JSON格式进行表示。每个文档可以存储不同的域集,但同一类型下的文档至应该有某种程度上的相似之处。类比传统的关系型数据库领域来说,类型相当于“行”。
|
|
|
|
|
|
|
|
|
|
##### 集群(cluster)
|
|
|
|
|
|
|
|
|
|
一个或者多个拥有相同cluster.name配置的节点组成, 它们共同承担数据和负载的压力。
|
|
|
|
|
|
|
|
|
|
##### 节点(node)
|
|
|
|
|
|
|
|
|
|
一个运行中的 Elasticsearch 实例称为一个节点。es中的节点分为三种类型:
|
|
|
|
|
|
|
|
|
|
主节点:负责管理集群范围内的所有变更,例如增加、删除索引,或者增加、删除节点等。 主节点并不需要涉及到文档级别的变更和搜索等操作。可以通过属性`node.master`进行设置。
|
|
|
|
|
|
|
|
|
|
数据节点:存储数据和其对应的倒排索引。默认每一个节点都是数据节点(包括主节点),可以通过`node.data`属性进行设置。
|
|
|
|
|
|
|
|
|
|
协调节点:如果`node.master`和`node.data`属性均为false,则此节点称为协调节点,用来响应客户请求,均衡每个节点的负载。
|
|
|
|
|
|
|
|
|
|
注意:
|
|
|
|
|
|
|
|
|
|
使用index和doc_type来组织数据。doc_type中的每条数据称为一个document,是一个JSON Object
|
|
|
|
|
|
|
|
|
|
ES分布式搜索,传统数据库遍历式搜索
|
|
|
|
|
|
|
|
|
|
案例解释:
|
|
|
|
|
|
|
|
|
|
要计算出2.38亿会员中有多少80后的已婚的北京男士:
|
|
|
|
|
|
|
|
|
|
传统数据库执行时间: 5个小时左右
|
|
|
|
|
|
|
|
|
|
ES执行时间:1分钟
|
|
|
|
|
|
|
|
|
|

|
|
|
|
|
|
|
|
|
|
##### 分片(Shards)
|
|
|
|
|
|
|
|
|
|
分片是Elasticsearch进行数据分布和扩展的基础。每个索引都可以被分割成多个分片,每个分片其实是一个独立的索引。分片使得Elasticsearch可以把巨大的数据集分散存储在多个节点上,这样可以实现:
|
|
|
|
|
|
|
|
|
|
水平扩展:随着数据量的增加,可以通过增加更多的节点来分摊数据和负载,从而提高处理能力
|
|
|
|
|
|
|
|
|
|
提升性能:搜索操作可以并行在多个分片上执行,每个分片处理的速度更快,整体搜索性能得以提升
|
|
|
|
|
|
|
|
|
|
##### 副本(Replicas)
|
|
|
|
|
|
|
|
|
|
副本是分片的复制,主要用于提高数据的可用性和搜索查询的并发处理能力。每个分片都可以有一个或多个副本,这些副本分布在不同的节点上,从而提供了:
|
|
|
|
|
|
|
|
|
|
数据可用性:当某个节点发生故障时,该节点上的分片如果有副本存在于其他节点上,那么这些副本可以保证数据不会丢失,并且服务还可以继续运行
|
|
|
|
|
|
|
|
|
|
负载均衡:读取操作(如搜索请求)可以在所有副本之间进行负载均衡,这样可以提高查询的吞吐量和响应速度
|
|
|
|
|
|
|
|
|
|
##### 定义分片和副本
|
|
|
|
|
|
|
|
|
|
创建索引时指定分片和副本数
|
|
|
|
|
|
|
|
|
|
当您通过Elasticsearch的REST API创建一个新的索引时,可以在请求体中使用settings部分来指定该索引的分片数(number_of_shards)和副本数(number_of_replicas)。以下是一个具体的示例:
|
|
|
|
|
|
|
|
|
|
```json
|
|
|
|
|
PUT /my_index
|
|
|
|
|
{
|
|
|
|
|
"settings": {
|
|
|
|
|
"index": {
|
|
|
|
|
"number_of_shards": 3, # 指定该索引将有3个主分片
|
|
|
|
|
"number_of_replicas": 2 # 每个主分片将有2个副本分片
|
|
|
|
|
}
|
|
|
|
|
}
|
|
|
|
|
}
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
这个例子中,PUT /my_index是创建名为my_index的索引的请求。在请求体中,settings部分指出这个索引将被分成3个主分片,并且每个主分片将会有2个副本分片。这意味着,总共会有9个分片(3个主分片 + 6个副本分片)被分布在集群中
|
|
|
|
|
|
|
|
|
|
主分片数量:一旦索引被创建,其主分片的数量就无法更改。因此,在创建时应谨慎选择合适的分片数量。
|
|
|
|
|
|
|
|
|
|
副本数量:与主分片数量不同,副本的数量是可以动态调整的。如果需要更多的数据冗余或查询吞吐量,可以增加副本的数量。
|
|
|
|
|
|
|
|
|
|
伸缩性与性能:选择分片和副本的数量时需要考虑数据量、查询负载和集群的硬件资源。过多的分片可能会增加集群的管理开销,而过少的分片可能会限制数据和查询的伸缩性。
|
|
|
|
|
|
|
|
|
|
**分片数的确定**
|
|
|
|
|
|
|
|
|
|
数据量预估:估计索引的总数据量大小。一般来说,每个分片处理20GB到50GB数据是比较理想的。这不是固定规则,但可以作为一个起点。
|
|
|
|
|
|
|
|
|
|
硬件资源:考虑你的硬件资源,尤其是内存和CPU。分片越多,消耗的资源也越多。确保你的Elasticsearch集群有足够的资源来处理这些分片。
|
|
|
|
|
|
|
|
|
|
写入吞吐量:如果你的应用会有大量的写入操作,更多的分片可能有助于提高写入性能,因为可以并行写入多个分片。
|
|
|
|
|
|
|
|
|
|
查询性能:更多的分片意味着查询可以并行于更多的分片上执行,这可能会提高查询性能。但是,如果每个查询都要访问大多数分片,那么管理过多的分片会减慢查询速度。
|
|
|
|
|
|
|
|
|
|
**副本数的确定**
|
|
|
|
|
|
|
|
|
|
数据可用性:至少有一个副本可以确保当某个节点失败时,数据不会丢失,并且Elasticsearch服务仍然可用。
|
|
|
|
|
|
|
|
|
|
读取性能:更多的副本意味着更高的读取吞吐量,因为读取请求可以在多个副本之间分配。如果你的应用主要是读取密集型的,增加副本数可以提高查询性能。
|
|
|
|
|
|
|
|
|
|
集群负载:考虑集群的整体负载。增加副本会提高数据冗余和读取性能,但也会增加存储需求和网络流量,因此需要确保你的硬件资源可以支持。
|